-
데이터베이스 조인의 모든것에 대해서 알아보자CS/데이터베이스 2022. 6. 19. 20:40반응형
정리한 내용은 다음과 같습니다.
전반적인 Join의 개념과 등장 배경
다양한 Join 방법(Inner Join, Outer Join, Self Join, Cross Join) + 옵티마이저와 힌트 맛보기
Join이 실제로 수행되는 과정(Nested Loop Join, Sort Merge Join, Hash Join)
조인이란?
한 데이터베이스 내의 여러 테이블의 레코드를 조합하여 하나의 열로 표현한 것입니다.
글보다는 사진으로 예시를 들어보겠습니다.
한 데이터베이스 내의 여러 테이블의 레코드를 조합하여 하나의 열로 표현한 것입니다.
=>
한 데이터베이스 내의 사원과 부서 테이블의 레코드(이름, 부서명)를 조합하여 하나의 (이름, 부서명) 테이블로 표현합니다.

조인 그림 예시(https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=seojinsu75&logNo=140200180551) 조인이 등장하게 된 이유(조인의 필요성)
관계형 데이터베이스에는 정보들이 하나의 테이블에 몰려 있지 않고 여러 곳의 테이블에 정규화되어 흩어져 있습니다.
문제는 사용자의 정보가 여러 곳에 흩어져 있기 때문에 원하는 데이터를 찾기 위해 여러 테이블을 조회해야 합니다.
따라서 조인이 등장하게 되었으며 조인을 통해 여러 테이블에 흩어져 있는 정보 중에서 사용자가 필요한 정보만 가져와서 가상의 테이블처럼 만들어서 결과를 보여줍니다.
조인의 종류

https://schatz37.tistory.com/2 위의 그림은 구글에 SQL Join을 검색하면 아주 쉽게 찾을 수 있는 그림입니다.
다양한 조인에 대하여 알아보겠습니다.
조인의 종류에 대해 설명하기 전에 다음과 같은 2개의 테이블이 존재한다고 가정하겠습니다.
1. 테이블 SAWON은 기업 Z의 모든 직원의 사번, 이름, 직급 정보가 담겨있습니다.
2. 테이블 LICENSE는 직원들이 소유하고 있는 자격증 정보가 담겨있습니다.

https://tragramming.tistory.com/74 여기서 가정해볼 수 있는 예외사항은 대략적으로 2가지입니다.
예외사항 1 : 자격증이 없는 사원이 있을 수 있다.
예외사항 2 : 자격증 기록은 있는데 자격증을 소유한 사람이 퇴사하여 SAWON 테이블에 해당 사원의 정보가 없다.
위의 예외사항을 반영한 SAWON 테이블과 LICENSE 테이블의 레코드들입니다.
가독성을 위해 SABUN이 같은 레코드들은 동일 선상에 표시하였습니다.

https://tragramming.tistory.com/74 1. 내부 조인 ( INNER JOIN)

INNER JOIN - 가장 흔히 사용되는 결합 방식으로 기본 조인 형식으로 간주됩니다.
- 각 테이블에서 조인 조건에 일치하는 데이터만 가져옵니다. (교집합)
- 내부 조인은 조인 구문에 기반한 2개의 테이블(A, B)의 칼럼 값을 결합함으로써 새로운 결과 테이블을 생성합니다.
- 명시적 조인과 암시적 조인으로 구분 지을 수 있습니다.
명시적 조인
ON 키워드를 조인에 대한 조인에 대한 구문을 지정하는 데 사용합니다.
SELECT * FROM SAWON A INNER JOIN LICENSE B ON A.SABUN = B.SABUN암시적 조인
컴마(,)를 사용하여 단순히 조인을 위한 여러 테이블을 나열하여 WHERE 절을 사용합니다.
SELECT * FROM SAWON A, LICENSE B WHERE A.SABUN = B.SABUN결과
A테이블과 B테이블의 사원번호가 같은 (조건에 부합하는 것만) SELECT 합니다.

https://tragramming.tistory.com/74 SABUN NAME RANK SABUN LICENSE_NM ----------- ------- ------- ----------- --------------- 2020012901 정영훈 사원 2020012901 정보처리기사 2020020201 정영훈3 사원 2020020201 정보관리기술사2. 외부 조인 (OUTER JOIN)

- 조인 조건에 일치하는 데이터 및 일치하지 않는 데이터를 모두 SELECT 합니다.
- 조인 조건에 일치하는 데이터가 없다면 NULL로 가져옵니다.
- 조인 대상 테이블에서 특정 테이블의 데이터가 모두 필요한 상황에서 외부 조인을 활용하여 효과적으로 결과 집합을 생성할 수 있습니다.
- INNER JOIN과 다르게 주 테이블이 어떤 테이블인지가 중요합니다. 그래서 어떤 테이블이 중심이 되느냐에 따라 LEFT OUTER JOIN , RIGHT OUTER JOIN , FULL OUTER JOIN으로 세분할 수 있습니다.
- LEFT OUTER JOIN은 왼쪽에 있는 테이블에 주 테이블, RIGHT OUTER JOIN은 오른쪽에 있는 테이블이 주 테이블, FULL OUTER JOIN은 양쪽 테이블 모두 주 테이블입니다.
2-1. LEFT OUTER JOIN
- 왼쪽 테이블이 주 테이블입니다.
- 조인 조건에 부합하는 데이터가 없으면 NULL을 있다면 해당 데이터를 SELECT 합니다.
쿼리문
SELECT * FROM SAWON A LEFT OUTER JOIN LICENSE B ON A.SABUN = B.SABUN;결과
A테이블을 기준으로 B테이블에 정보가 있으면 가져오고 없으면 NULL을 가져옵니다.

https://tragramming.tistory.com/74 SABUN NAME RANK SABUN LICENSE_NM -------- ------ ------ ---------- ---------------- 2020012901 정영훈 사원 2020012901 정보처리기사 2020020201 정영훈3 사원 2020020201 정보관리기술사 2020012902 정영훈2 사원 NULL NULL 2020020202 정영훈4 사원 NULL NULL 2020020203 정영훈5 사원 NULL NULL 2020020204 정영훈6 사원 NULL NULL2-2 RIGHT OUTER JOIN
- 오른쪽 테이블이 주 테이블이 됩니다.
- 조인 조건에 부합하는 데이터가 왼쪽에 있으면 해당 데이터를 없다면 NULL을 SELECT 합니다.
쿼리문
SELECT * FROM SAWON A RIGHT OUTER JOIN LICENSE B ON A.SABUN = B.SABUN;결과

https://tragramming.tistory.com/74 SABUN NAME RANK SABUN LICENSE_NM -------- ------ ------ ---------- ---------------- 2020012901 정영훈 사원 2020012901 정보처리기사 2020020201 정영훈3 사원 2020020201 정보관리기술사 NULL NULL NULL 2012020204 정보처리산업기사2-3 FULL OUTER JOIN
- 양쪽 모두 주 테이블이 됩니다.
- 조인 조건에 부합하는 데이터가 왼쪽 또는 오른쪽에 있으면 해당 데이터를 없다면 NULL을 SELECT 합니다.
쿼리문
SELECT * FROM SAWON A FULL OUTER JOIN LICENSE B ON A.SABUN = B.SABUN;결과

https://tragramming.tistory.com/74 SABUN NAME RANK SABUN LICENSE_NM -------- ------ ------ ---------- ---------------- 2020012901 정영훈 사원 2020012901 정보처리기사 2020012902 정영훈2 사원 NULL NULL 2020020201 정영훈3 사원 2020020201 정보관리기술사 2020020202 정영훈4 사원 NULL NULL 2020020203 정영훈5 사원 NULL NULL 2020020204 정영훈6 사원 NULL NULL NULL NULL NULL 2012020204 정보관리산업기사3. CROSS JOIN

https://w3cschoool.com/mysql-cross-join - 두 테이블 조인 시 가능한 모든 경우의 레코드를 SELECT 합니다.
- INNER, OUTER JOIN이 특정 조건에 따라 조인된다면, CROSS JOIN은 별도의 조건을 기술하지 않습니다.
- 예를 들어 A에는 25개의 레코드가 존재하고 B에는 20개의 레코드가 존재한다면 CROSS JOIN은 총 25*20 = 500 개의 레코드가 SELECT 됩니다.
쿼리문
SELECT * FROM SAWON A CROSS JOIN LICENSE B;결과

https://tragramming.tistory.com/74 SABUN NAME RANK SABUN LICENSE_NM -------- ------ ------ ---------- ---------------- 2020012901 정영훈 사원 2020012901 정보처리기사 2020012901 정영훈 사원 2020020201 정보관리기술사 2020012901 정영훈 사원 2012020204 정보관리산업기사 2020012902 정영훈2 사원 2020012901 정보처리기사 2020012902 정영훈2 사원 2020020201 정보관리기술사 2020012902 정영훈2 사원 2012020204 정보관리산업기사 2020020201 정영훈3 사원 2020012901 정보처리기사 2020020201 정영훈3 사원 2020020201 정보관리기술사 2020020201 정영훈3 사원 2012020204 정보관리산업기사 2020020202 정영훈4 사원 2020012901 정보처리기사 2020020202 정영훈4 사원 2020020201 정보관리기술사 2020020202 정영훈4 사원 2012020204 정보관리산업기사 2020020203 정영훈5 사원 2020012901 정보처리기사 2020020203 정영훈5 사원 2020020201 정보관리기술사 2020020203 정영훈5 사원 2012020204 정보관리산업기사 2020020204 정영훈6 사원 2020012901 정보처리기사 2020020204 정영훈6 사원 2020020201 정보관리기술사 2020020204 정영훈6 사원 2012020204 정보관리산업기사4. SELF JOIN

https://iamjaeeuncho.github.io/study/SQL_Join/ - 테이블이 자기 자신을 마치 다른 테이블처럼 취급하여 조인합니다.
- 주 테이블과 서브 테이블의 칼럼이 모두 같기 때문에, 특정 열을 명시할 때 열이 모호하다는 오류가 발생할 수 있습니다. 이런 점에서 반드시 별칭(ALIAS)을 사용하여 조인하는 것을 권고합니다.
쿼리문
SELECT * FROM SAWON A JOIN SAWON B ON A.SABUN = B.SABUN;결과

https://tragramming.tistory.com/74 SABUN NAME RANK SABUN NAME RANK ---------- ------- ------ ----------- ------ ------ 2020012901 정영훈 사원 2020012901 정영훈 사원 2020012902 정영훈2 사원 2020012902 정영훈2 사원 2020020201 정영훈3 사원 2020020201 정영훈3 사원 2020020202 정영훈4 사원 2020020202 정영훈4 사원 2020020203 정영훈5 사원 2020020203 정영훈5 사원 2020020204 정영훈6 사원 2020020204 정영훈6 사원자기 자신을 JOIN 해서 도대체 어디에 사용할까요?
한 테이블에 존재하는 칼럼 사이에서 의미 있는 관계가 존재할 때 셀프 조인을 활용할 수 있습니다.
예를 들어 같은 값을 공유하고 있는 row를 알고 싶을 때 활용할 수 있습니다.
아래 그림과 같은 테이블이 존재한다고 가정해보겠습니다.
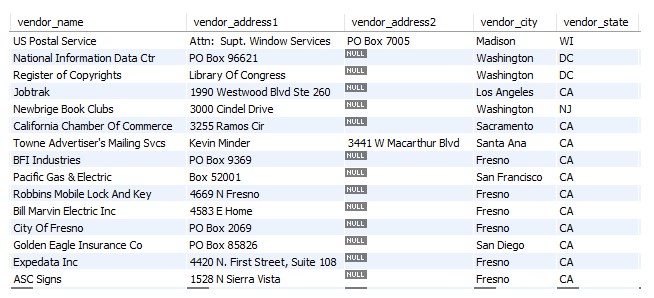
https://minor-research.tistory.com/24 각 row는 벤더의 정보를 담고 있으며 벤더가 소재하고 있는 city(vendor_city)와 state(vendor_state)를 알 수 있습니다.
이때 자기 소재지에 경쟁하는 다른 벤더들이 존재하는지 궁금하다면 셀프 조인을 활용할 수 있습니다.
city와 state가 같고 name이 다른 조건으로 테이블을 셀프 조인하면 같은 city와 state에 존재하는 다른 모든 벤더가 선택됩니다.
이때 한 지역에 벤더가 3개 이상일 경우 vendor_name이 중복되어 표시되기 때문에 DISTINCT를 이용해 중복 값을 제거해주면 아래 테이블과 같은 city와 state에 존재하는 벤더들이 선택됩니다.
쿼리문
SELECT DISTINCT v1.vendor_name, v1.vendor_city, v1.vendor_state FROM vendors v1 JOIN vendors v2 ON v1.vendor_city = v2.vendor_city AND v1.vendor_state = v2.vendor_state AND v1 vendor_name <> v2.vendor_state결과

https://minor-research.tistory.com/24 조인 알고리즘
위에서 다양한 조인 기법에 대해서 알아보았습니다.
점점 많은 테이블을 조인하게 되면 쿼리를 수행하는데 꽤 많은 시간이 소요됩니다.
조인은 어떤 원리로 이루어지는지 학습하고 효율적인 조인의 방법에 대해 알아보고자 합니다.
SQL에서 조인 연산을 수행할 때 내부적으로 선택되는 대표적인 세 가지 방식을 소개하겠습니다.
1. Nested Loops Join
2. Sort Merge Join
3. Hash Join
위의 조인 알고리즘 중 어떤 알고리즘을 선택할지는 데이터의 크기, 결합 키(Key), 인덱스(Index)와 같은 요인에 따라 옵티마이저가 결정하게 됩니다.
옵티마이저란?
SQL 쿼리를 작성해서 실행하면 해당 쿼리는 옵티마이저로 전송됩니다.
데이터의 크기, 결합 키, 인덱스 유무 등의 여러 조건을 고려해서 다양한 실행계획을 작성하고 가장 낮은 비용을 가진 실행계획을 선택합니다.
1. Nested Loops Join
직역해보자면 중첩 루프 조인입니다.
즉, 중첩 반복을 사용하는 알고리즘입니다.

https://schatz37.tistory.com/2 위의 그림을 보면 for문 2개를 사용하여 중첩 반복문을 수행하는 것이 떠오릅니다.
Table A는 첫 번째 행에서 출발하여 Table B의 모든 행을 스캔하고 결합 조건이 맞으면 값을 리턴합니다.
Table A의 첫 번째 행의 스캔이 끝나면 두 번째 행이 Table B의 모든 행을 스캔합니다.
위의 과정을 Table A의 마지막 행이 Table B의 모든 행을 스캔하게 되면 연산이 끝나게 됩니다.
모든 경우를 탐색하기 때문에 접근하게 되는 레코드 수는 Table A의 레코드 수 (5) * Table B의 레코드 수(10) = 50입니다.
Nested Loops Join의 성능을 높이기 위해서는 어떻게 해야 할까요?
결론부터 말하자면 "구동 테이블이 작을수록 , 내부 테이블의 결합 키 필드에 인덱스가 존재"라는 조건을 따르는 경우에 성능을 높일 수 있습니다.
구동 테이블? 내부 테이블? 인덱스?
구동 테이블이란 조인이 진행될 때 먼저 액세스 되어 주도하는 테이블입니다.
위의 예시에서는 Table A가 구동 테이블이 되고 Table B는 내부 테이블이 됩니다.
인덱스란 우리가 책을 볼 때 목차를 보고 원하는 부분으로 이동하여 시간을 단축하듯이 추가적인 공간과 작업을 통해 데이터를 정렬시킴으로써 해당 Table의 레코드들을 Full Scan 하지 않고 빠르게 수행할 수 있습니다.
예를 들어 Table B의 최댓값을 탐색하고 싶습니다.
정렬되어 있지 않다면 Full Scan 하면서 최댓값을 탐색해야 합니다. (O(n))
만약 크기가 작은 순 -> 큰 순으로 정렬되어 있다면 마지막 레코드만 조회하면 되기 때문에 O(1) 만에 수행 가능합니다.
이를 그림으로 보자면 다음과 같은 그림으로 나타낼 수 있습니다.

https://schatz37.tistory.com/2 내부 테이블(Inner Table)에 만약 인덱스가 존재하면 모든 행을 스캔할 필요가 사라지게 돼서 효율적으로 변하게 됩니다.
구동 테이블(Driving Table)이 작을수록 탐색하는 수가 줄어들게 됩니다.
이를 통해 Table A의 레코드 수 * Table B의 레코드 수가 탐색되는 연산을 줄일 수 있게 됩니다.
구동 테이블은 어떻게 선정될까요?
Join을 효율적으로 수행하기 위해서는 적절하게 구동 테이블이 선정되어야 합니다.
이러한 과정을 옵티마이저가 최적의 실행계획에 따라 결정하게 됩니다.
하지만 Outer Join은 위 규칙과 무관하게 구동테이블이 정해집니다.
Inner Join은 어느 테이블을 먼저 읽어도 결과가 달라지지 않기 때문에 옵티마이저가 조인의 순서를 최적화를 수행할 수 있습니다.
하지만 Outer Join은 반드시 Outer가 되는 테이블을 먼저 읽어야 하기 때문에 조인의 순서를 선택할 수 없습니다.
우리가 직접 실행계획을 제어할 수 없을까요?
DBMS 마다 다를 순 있지만 "힌트(Hint)"라는 개념을 사용하면 사용자가 실행계획을 제어할 수 있습니다.
하지만 실행계획을 제어할 경우에 계속해서 변하는 데이터의 양과 인덱스가 DB를 운영하면서 계속 바뀔 수 있기 때문에 어떤 시점에 적절했던 실행계획이 또 다른 시점에는 부적절해질 수 있습니다.
2. Sort Merge Join
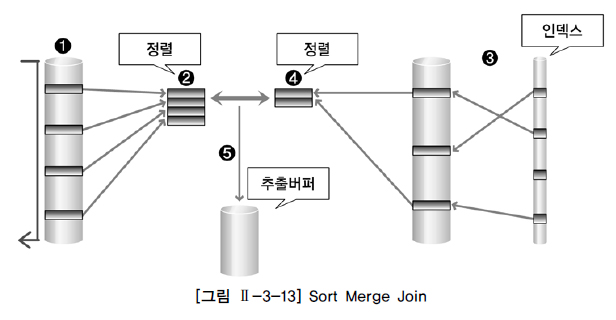
https://devlog.changhee.me/posts/Join%EA%B8%B0%EB%B2%95_%EC%A0%95%EB%A6%AC/ 1. 선행 테이블에서 주어진 조건을 만족하는 행을 찾습니다.
2. 선행 테이블의 조인 키를 기준으로 정렬 작업을 수행합니다.
3. 후행 테이블에서 주어진 조건을 만족하는 행을 찾습니다.
4. 후행 테이블의 조인 키를 기준으로 정렬 작업을 수행합니다.
5. 정렬된 결과를 이용하여 조인을 수행하며 조인에 성공하면 추출 버퍼에 넣습니다.
언제 사용될까요?
조인 칼럼의 인덱스가 존재하지 않을 경우에도 사용할 수 있는 기법입니다.
조인 조건으로 < , > , <= , >= 와 같은 범위 비교 연산자가 사용된 경우
인덱스 사용에 따른 랜덤 액세스의 오버헤드가 많은 경우
3. Hash Join

1. 둘 중 작은 집합(Build Input)을 읽어 Hash Area에 해시 테이블을 생성합니다.
2. 반대쪽 큰 집합(Probe Input)을 읽어 해시 테이블을 탐색하면서 JOIN 합니다.
3. 해시 함수에서 리턴 받은 버킷 주소로 찾아가 해시 체인을 스캔하면서 데이터를 찾습니다.
언제 사용될까요?
Sort Merge Join을 하기에는 두 테이블이 너무 커 Sort 부하가 심할 때
Join 칼럼에 적당한 인덱스가 없어 Nested Loop Join이 비효율적일 때
출처
4 장 여러 테이블의 결합을 통한 검색 (JOIN 검색) | 통계데이터베이스
아래의 자료는 자료값이 탭으로 구분된 자료이고 첫번째 라인은 변수명이다. 위에서 생성한 테이블에 각각 입력하여라.
bigdata.dongguk.ac.kr
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=seojinsu75&logNo=140200180551
Chap 4. Join 을 배웁니다
-------------------------------------------------------------------------------------------...
blog.naver.com
https://velog.io/@ragnarok_code/DataBase-%EC%A1%B0%EC%9D%B8Join%EC%9D%B4%EB%9E%80
[DataBase] 조인(Join)이란 ?
한 데이터베이스 내의 여러 테이블의 레코드를 조합하여 하나의 열로 표현한 것이다.따라서 조인은 테이블로서 저장되거나, 그 자체로 이용할 수 있는 결과 셋을 만들어 낸다.관계형 데이터베
velog.io
https://tragramming.tistory.com/74
[Join] ANSI Join & Oracle Join, Join의 종류
지난 Join의 정의 및 문법에 관한 포스팅에 이어 ANSI Join & Oracle Join, Join의 종류에 대해 이야기하고자 한다. ANSI Join vs ORACLE Join SQL은 데이터베이스를 관리하기 위해 만들어진 프로그래밍 언어이며,
tragramming.tistory.com
https://schatz37.tistory.com/2
[SQL] "성능 관점"에서 보는 결합(Join)
0. 들어가며 결합(Join) 은 SQL 사용하게 되면 반드시 활용하는 기능입니다. Inner Join, Outer Join 등 다양한 결합 방법이 존재하고 우리는 이를 활용해서 DB에 있는 여러 테이블을 활용할 수 있습니다.
schatz37.tistory.com
https://coding-factory.tistory.com/758
[DB] 데이터베이스 HASH JOIN (해시 조인)에 대하여
HASH JOIN이란? HASH 조인은 조인될 두 테이블 중 하나를 해시 테이블로 선정하여 조인될 테이블의 조인 키 값을 해시 알고리즘으로 비교하여 매치되는 결과값을 얻는 방식입니다. HASH JOIN은 비용 기
coding-factory.tistory.com
https://coding-factory.tistory.com/757
[DB] 데이터베이스 SORT MERGE JOIN (정렬 병합 조인)에 대하여
SORT MERGE JOIN이란? 조회의 범위가 많을 때 주로 사용하는 조인 방법론이며 양쪽 테이블을 각각 Access 하여 그 결과를 정렬하고 그 정렬한 결과를 차례로 Scan 해 나가면서 연결고리의 조건으로 Merg
coding-factory.tistory.com
'CS > 데이터베이스' 카테고리의 다른 글
MySQL workbench 계정 추가하기 (0) 2022.07.16 MySQL index 적용해보기 + Full Text Index 적용 (0) 2022.07.04 데이터베이스 Replication (0) 2022.06.02 DB 옵티마이저와 실행계획 (0) 2022.06.01 MySQL 테이블 생성 (0) 2022.05.24