-
Spring Boot Distributed SchedulingSpring Framework 2024. 6. 30. 21:25반응형
개요
최근에 Spring Batch 대신 @Scheduled 활용해 보기라는 주제로 글을 작성했던 적이 있는데 비슷한 주제로 Spring I/O 유튜브에 Spring Boot Distributed Scheduling 주제가 올라와서 이를 정리해보고자 합니다.
Spring의 @Schedueld
대부분의 software의 문제는 매 1분마다 실행되는 job을 통해 해결할 수 있습니다.
Spring에서는 특정 주기로 반복되는 작업을 실행하기 위해 @Scheduled 어노테이션을 지원합니다.
하지만 서버 한대가 아니라 여러대에서 구동되는 환경이라면 각 서버에서 반복되는 작업이 개별적으로 수행되어 Race Condition이 발생할 수 있습니다.

위의 그림처럼 우리는 각 자원이 이상적으로 분배될 것이라고 기대되지만 여러 대의 서버가 하나의 자원에 경합될 수 있습니다.

또한 위의 그림같은 이상적인 분산환경은 현실과는 다릅니다.
멀 티쓰레딩환경과 분산환경에서 우리의 BackGround Job을 안전하게 실행하려면 어떻게 해야 할까요?
아래 코드에서 발생할 수 있는 잠재적인 문제들을 살펴보겠습니다.

만약 Application이 중간에 오류가 발생해서 종료된다면 어떻게 될까?

newCard를 적재하고, newCard를 갱신하려고 하는데 사이 시점에 버그가 발생한다면?

데이터 정합성이 틀어짐 데이터 정합성이 예상하지 못하게 틀어질 수 있습니다.
이런경우에는 Spring의 @Transactional 어노테이션을 활용하여 데이터 정합성을 유지할 수 있습니다.
만약 데이터의 크기가 너무 크다면 어떨까요?
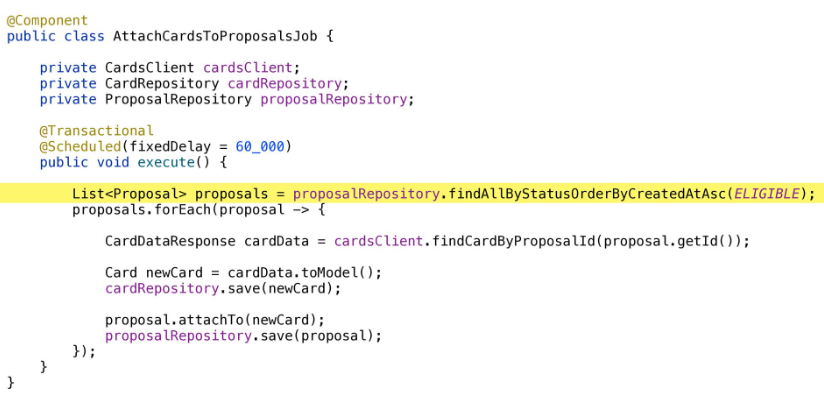
findAll을 수행하다가 데이터가 너무 많다면 메모리가 부족해질 수 있습니다.
메모리보다 데이터가 많아진다면 최악의 경우 OOM이 발생할 수 도 있습니다.

findTop50을 활용하여 50개씩 데이터를 가져옴으로써 메모리 문제를 해결할 수 있습니다.
하지만 위의 코드는 여전히 문제가 있습니다.
최상단에 선언된 @Trnasactional 어노테이션 때문에 Long Transaction이 수행될 수 있습니다.

이로 인해 JPA의 Entity Manager에는 작업이 계속 쌓이게 되면서 여전히 OOM이 발생할 수 있습니다.
이를 방지하기 위해서는 Short Transaction으로 변환해야 합니다.

이제 50개의 작업마다 트랜잭션이 수행되므로 대용량 데이터로인한 문제가 발생하지 않습니다.
만약 Application이 Cluster에서 멀티인스턴스로 구동된다면 어떨까요?

2대의 인스턴스가 동작한다고 가정해보면 작업이 2번 수행될 수 있습니다.
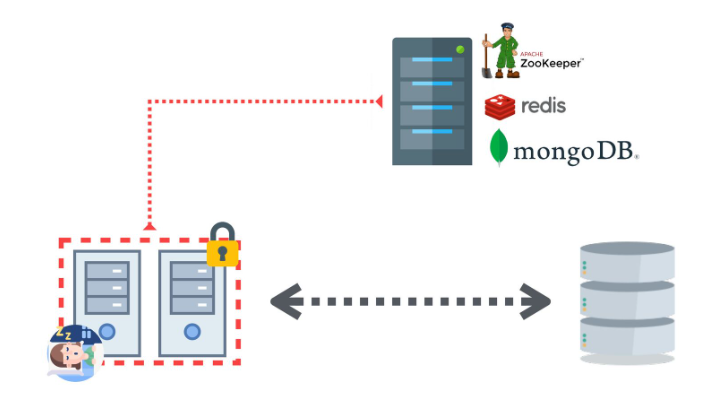
이런 경우 분산락을 고려해 볼 수 있습니다.
다만 하나의 인스턴스에서 동작하고, 나머지 인스턴스는 쉬는 상태가 됩니다.
어떻게 하면 가용성을 높일 수 있을까요?

이제 Persismstic_write lock을 통하여 두 인스턴스가 경합하면서 자원을 점유하게 됩니다.
만약 더 높은 처리량이 필요하면 어떨까요?

현재 상황에서는 인스턴스가 2대에서 3대로 scale up 한 상황이지만 처리량이 늘어나지 않습니다.
Kafka 같은 Queue를 활용하게 된다면 3대에서 작업을 Consume 하면서 처리량을 늘려볼 수도 있지만 Database로는 해결할 수 없을까요?


skip_locked를 활용하게 된다면 이미 리소스가 점유되어 있는 경우에는 넘어가게 되면서 처리량을 높일 수 있습니다.
이제 고가용성도 확보되고 확장성도 같이 확보되었습니다.

여기서 더 나아가면 forEach 반복마다 INSERT, UPDATE하는 작업을 Hibernate batch size로 bulk insert 해줄 수 있습니다.
만약 네트워크에 문제가 있으면 어떨까요?

외부 Client를 호출하다가 timeout이 발생하거나 일시적인 예외가 발생하면 어떨까요?
backOff 등을 주면서 재시도를 수행해 볼 수 있으며 멱등성(idempotency)이 지켜지는지도 중요합니다.
결론
위의 사례를 기반으로 background job을 구성할 때는 다음을 고려해야 합니다.
- application crash에 복구할 수 있어야 한다.
- 대용량의 데이터를 처리할 수 있어야 한다.
- 가용성을 확보하고 확장가능한 구조여야 한다.
- 높은 처리량을 최적화해야 할 수 있어야 한다.
background job은 생각보다 어려울 수 있습니다.
참고자료
https://www.youtube.com/watch?v=ghpljMg8Ecc&t=2181s
'Spring Framework' 카테고리의 다른 글
Spring Bean 이름은 왜 소문자로 시작할까? (0) 2024.11.03 분산시스템에서 로깅 트레이싱 전파는 어떻게 이루어질까? (0) 2024.10.26 프로젝트에 Feature Flag 적용하기 (0) 2024.06.01 Spring Batch 대신 @Scheduled 활용해보기 (1) 2024.05.08 Adaptor 패턴으로 호출가능한 Local 환경 만들기 (0) 2024.03.08