MongoDB 인덱스란?
개요
공식문서를 기반으로 MongoDB의 인덱스를 알아보는 시간을 가져보려고 합니다.
인덱스 생성법, 인덱스의 타입, 인덱스의 속성에 대해 정리해보고자 합니다.
인덱스란?
인덱스는 쿼리의 효율적인 실행을 지원합니다.
인덱스가 없을 경우에 쿼리 결과를 반환하기 위해 컬렉션의 모든 문서를 스캔해야 합니다.
하지만 적합한 인덱스가 존재하면 스캔하는 문서의 수를 줄일 수 있습니다.
인덱스는 읽기 작업의 성능을 향상시키지만, 쓰기 작업에는 성능에 부정적인 영향을 미칩니다.
즉, 읽기와 쓰기의 비율을 잘 고려해서 적용해야 합니다.
MongoDB의 인덱스는 내부적으로는 B-Tree 데이터 구조를 활용합니다.
기본적으로 지원하는 인덱스
_id 필드에 고유 인덱스를 생성하며 해당 인덱스는 삭제할 수 없습니다.
인덱스 만드는 방법
db.collection.createIndex( { name: -1 } )
내림차순으로 name이라는 필드에 인덱스를 생성하는 방법입니다.
db.<collection>.createIndex(
{ <field>: <value> },
{ name: "<indexName>" }
)인덱스를 생성할때는 이름을 지정할 수도 있고 지정하지 않으면 기본적인 전략에 의해 만들어집니다.
기본 전략은 key, value사이에 언더스코어(_)가 붙어 name_-1 이라는 인덱스의 이름으로 생성될 것입니다.
인덱스 확인
db.collection.getIndexes()인덱스가 정상적으로 만들어졌는데 확인할 수 있습니다.
[
{ v: 2, key: { _id: 1 }, name: '_id_' },
{ v: 2, key: { name: -1 }, name: 'name_-1' }
]기본적으로 id에 대한 인덱스가 존재하였고 name 필드에도 인덱스를 생성하기 때문에 존재하는 것을 확인할 수 있습니다.
인덱스 삭제
db.<collection>.dropIndex("<indexName>")
인덱스의 타입
단일 필드에 적용하는 Single Field Index
db.students.createIndex( { gpa: 1 } )
여러개의 필드에 적용하는 Compound Index
db.leaderboard.createIndex( { score: -1, username: 1 } )
복합인덱스에서는 정렬 순서에 따라 쿼리가 인덱스를 타지 않을 수 있어서 주의해야 합니다.
db.leaderboard.createIndex( { score: -1, username: 1 } ) // (1) 지원됨
db.leaderboard.find().sort( { score: 1, username: -1 } ) // (2) 지원됨
db.leaderboard.find().sort( { score: 1, username: 1 } ) // (3) 지원되지 않음
db.leaderboard.find().sort( { username: 1, score: -1, } ) // (4) 지원되지 않음 필드 순서 유의
(4) 번은 (1) 번과 무슨 차이야?라고 생각되지만 인덱스를 생성했던 필드의 순서를 유의해야 합니다.
배열값이 포함된 필드에 적용하는 Multikey Index
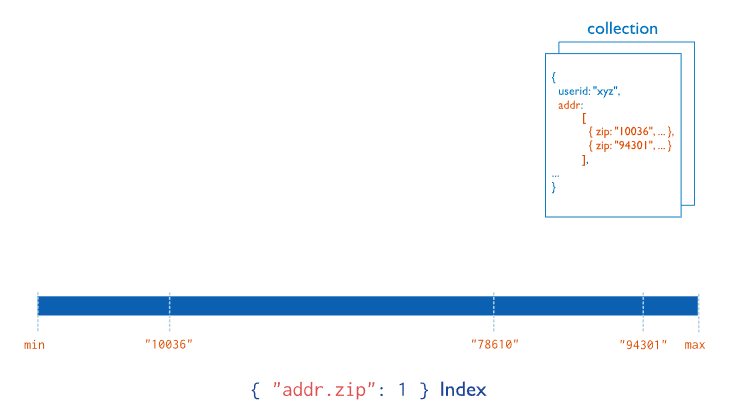
db.<collection>.createIndex( { <arrayField>: <sortOrder> } )addr.zip 필드에 multikey index를 활용할 수 있습니다.
검색기능을 지원하는 Text Index
db.<collection>.createIndex(
{ <field>: "text" },
{ default_language: <language> }
)mysql의 full-text index처럼 텍스트에 대한 검색을 지원하는 index입니다.
여러 개의 필드에 인덱스를 한 번에 걸 수 있는 Wildcard Index
db.collection.createIndex( { "<field>.$**": <sortOrder> } )
이외에도 활용할 수 있는 index
- 지리공간 좌표계에 사용할 수 있는 Geospatial Index
- hash function을 활용하는 hash index
인덱스의 속성
인덱스를 사용하는 방식 및 인덱스가 저장되는 방식에 영향을 줄 수 있는 속성을 정의할 수 있습니다.
Case-Insensitive Index
db.createCollection("fruit")
db.fruit.createIndex( { type: 1},
{ collation: { locale: 'en', strength: 2 } } )
db.fruit.insertMany( [
{ type: "apple" },
{ type: "Apple" },
{ type: "APPLE" }
] )
db.fruit.find( { type: "apple" } ) // does not use index, finds one result
db.fruit.find( { type: "apple" } ).collation( { locale: 'en', strength: 2 } )
// uses the index, finds three results
db.fruit.find( { type: "apple" } ).collation( { locale: 'en', strength: 1 } )
// does not use the index, finds three results대소문자를 구분하지 않는 인덱스를 활용할 수 있습니다.
Hidden Index
db.addresses.createIndex(
{ borough: 1 },
{ hidden: true }
);인덱스를 삭제하지 않고도 숨김 처리 하기
Partial Index
db.restaurants.createIndex(
{ cuisine: 1, name: 1 },
{ partialFilterExpression: { rating: { $gt: 5 } } }
)부분 인덱스는 인덱스에 대한 하위 집합을 인덱스 지원하면서 인덱스 관리에 드는 비용을 절감할 수 있습니다.
rating이 5보다 클 경우에만 인덱스가 생성되고 인덱스의 조건인 5보다 큰 경우에 위배되는 상황에서는 인덱스를 활용하지 않습니다.
Sparse Index
optional filed와 같이 문서에 존재하지 않는 필드를 색인화하는데 유용합니다.
TTL Index
일정 시간이 지나면 컬렉션에서 문서를 자동으로 제거하는 인덱스
사용자 세션, 로그 또는 캐시 항목등을 활용할 수 있습니다.
Unique Index
중복된 값을 허용하지 않는 인덱스