동시 트랜잭션(Concurrent Transaction)
지난번에 트랜잭션에 대하여 알아보았습니다
트랜잭션(Transaction)이란?
트랜잭션(Transaction)의 정의 Transaction은 "거래"라는 뜻을 가지지만 컴퓨터 과학분야에서는 "쪼개질 수 없는 업무처리의 단위"를 의미합니다. 데이터베이스의 상태를 변환시키는 하나의 논리적 기
junuuu.tistory.com
간단하게 복습하자면 트랜잭션이란
데이터베이스의 상태를 변환시키는 하나의 논리적 기능을 수행하기 위해 작업의 단위 또는 한꺼번에 모두 수행되어야 할 일련의 연산들을 의미합니다.
Concurrent Transaction이란?
트랜잭션A와 트랜잭션 B가 있다면 A를 끝내고 B를 수행하는것이 아닌 A와B를 동시에 수행하는 것
왜 Concurrent Transaction을 사용할까요?
CPU 와 I/O 는 병렬적으로 수행할 수 있기 때문에 Concurrent Transaction을 허용해야 자원을 효율적으로 사용할 수 있으며 연산속도를 증가시킬 수 있습니다.
Concurrent Transaction을 수행할 때 발생할 수 있는 문제점
A계좌에는 100만원 있고 B계좌에는 200만원이 있다고 가정하겠습니다.
트랜잭션1 : A가 계좌에서 B에게 10만원을 보냄
트랜잭션2 : A계좌의 10%에 해당하는 돈을 B에게 보냄
동시에 일어났을 때
Case1)
트랜잭션1이 A의 계좌(100만원)를 읽고 10만원을 뺀후 A를 저장합니다. A = 90
트랜잭션2가 A의 계좌(90만원)를 읽고 10%를 뺀후 A를 저장합니다. A = 81
트랜잭션1이 B의 계좌(200만원)를 읽고 10만원을 더한 후 B를 저장합니다. B = 210
트랜잭션2가 B의 계좌(210만원)를 읽고 A계좌(90만원)의 10%에 해당하는 값(9만원)을 더한후 B에 저장합니다. B = 219
A+ B = 300만원이 유지되므로 동시에 일어났지만 문제가 발생하지 않음
Case2)
트랜잭션1이 A의 계좌(100만원)를 읽고 10만원을 뺍니다. (A = 90이지만 저장이 빠져있음!)
트랜잭션2가 A의 계좌(100만원)를 읽고 10%를 뺀 후 A를 저장합니다. A = 90
트랜잭션1이 A에 값을 저장합니다. A = 90
트랜잭션2가 B의 계좌(200만원)를 읽고 10만원을 더 한 후 B를 저장합니다. B= 210
트랜잭션2가 B의 계좌(210만원)를 읽고 A의 계좌(100만원) 10%에 해당하는 값(10만원)을 더한후 B에 저장합니다. B= 220
A + B = 310만원으로 문제가 발생하였습니다.
이것을 해결하기 위해서는 Conflict serializability 해야 합니다.
Serializability(직렬성)
Conflict serializability 하다 = ( conflict equivalent schedules를 만들 수 있다.)
1. read끼리는 앞 뒤 순서에 상관이 없다.
2. 한쪽은 write 한쪽은 read일 때는 순서가 중요하다.
3. write 끼리는 순서가 중요하다.
결론 : read 빼고는 순서가 중요하다.

위의 그림은 Conflict serializability 하지 않음 ( T4의 write위치를 I(1)으로 바꾸면 read , write와 순서가 바뀌기 때문에 안됨)

위의 그림은 B에 대하여 write, read의 순서가 바뀌었기 때문에 Conflict serializability 하지 않음 . 하지만 Conflict equivanlent 하지 않아도 같은 결과를 만들어 낼 수 있음
View serializability = View Equivalent하다
1. T(1)에서 처음 A를 읽으면 T(1)는 항상 처음 A를 읽어야 함

2. T(2)가 쓴값을 T(3)가 읽으면 S`또한 T(2)가 쓴값을 T(3)가 읽어야 함 (맨위 우측의 빈칸이 T3입니다)

3. T(3) 에서 마지막으로 업데이트했다면 S`에서도 T(3)에 마지막으로 업데이트 해야한다.(맨위 우측의 빈칸이 T3입니다)

예시문제

S는 View serializable 하다( conflict serializable 하면 view serializable 하지만 view serializable한 것은 conflict serializable 하지 않을 수 있다)
Recoverability
단일 트랜잭션 에서는 트랜잭션이 실패되면 버리면 되지만 concurrent 트랜잭션에서는 의존성을 가진다.
의존성을 가진다는 것은 T(I)가 쓴 값을 T(j)가 읽는 경우를 의미합니다.
Recoverable 조건
T(j) 가 T(i)에 의존적인 경우 T(i)는 T(j)보다 빨리 committed 되어야 함
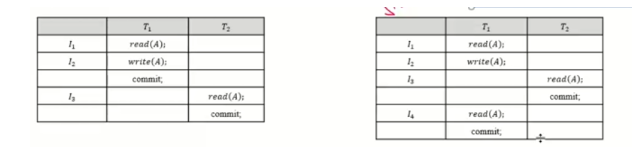
위의 그림에서 왼쪽그림은 Recoverable 하다
위의 그림에서 오른쪽 그림은 Recoverable 하지 않다. T(2)는 T(1)에 의존적이므로 T(1)이 T(2) 보다 빨리 committed 되어야 한다.
T(1)의 I(4)에서 Failed 되면 트랜잭션이 취소되는데 T(2)는 commit된다면 이상한 상황이 연출됨
Cascadeless schedule

만약 왼쪽그림에서 I(7)에서 Failed 되면 T1, T2, T3 트랜잭션 모두 취소해야 함. 이를보고 Cascade 하다고 하며 이를 오른쪽으로 피하는게 좋음.
Precedence graph 를 통해 Serialiability Test 방법을 해보자
G = (V, E) Graph 는 Vertex와 Edge의 집합
V = transactions
T(I) -> T(j) 로 간선을 긋는다 만약 아래와 같다면
T(I) write(A) -> T(j) read(A)
T(I) read(A) -> T(j) write(A)
T(I) write(A) -> T(j) write(A)
그래프가 원을 그리면 S는 conflict serializable 하지 않고 그래프가 원을 그리지 않으면 S는 conflict serializable 합니다. (원을 그린다는말은 cycle이 생긴다는 말)

원(cycle)을 그리기 때문에 conflict serializable 하지 않다.
그러면 어떻게 Concurrent Transaction을 수행할 수 있을까?
Naïve approach (트랜잭션이 수행될 때 데이터베이스 전체를 lock 해버리는 것)
하지만 이러면 단일 트랜잭션을 수행하는것과 동일할 것입니다.
따라서 lock을 어느 범위로 걸어버릴 것인가를 정하는것이 데이터베이스 자원을 효율적으로 사용하는 것을 정하게 됩니다.
데이터베이스 전체를 lock해버리게 되면 Conflict serializable 하지만 자원이 효율적으로 사용되지 않음
만약 데이터베이스 테이블을 lock해버리게 되면 Conflict serializable 하지 않을 수 있지만 자원이 효율적으로 사용됨
따라서 이 둘사이를 조절하며 자원은 효율적으로 사용하지만 Conflict serialziable 하도록 하는것이 우리의 목표