분산시스템에서 로깅 트레이싱 전파는 어떻게 이루어질까?
대상 독자
logback과 MDC를 활용하여 kafka, coroutine, async에도 트레이싱 전파를 어떻게 하는지 알고 싶으신 분들
개요
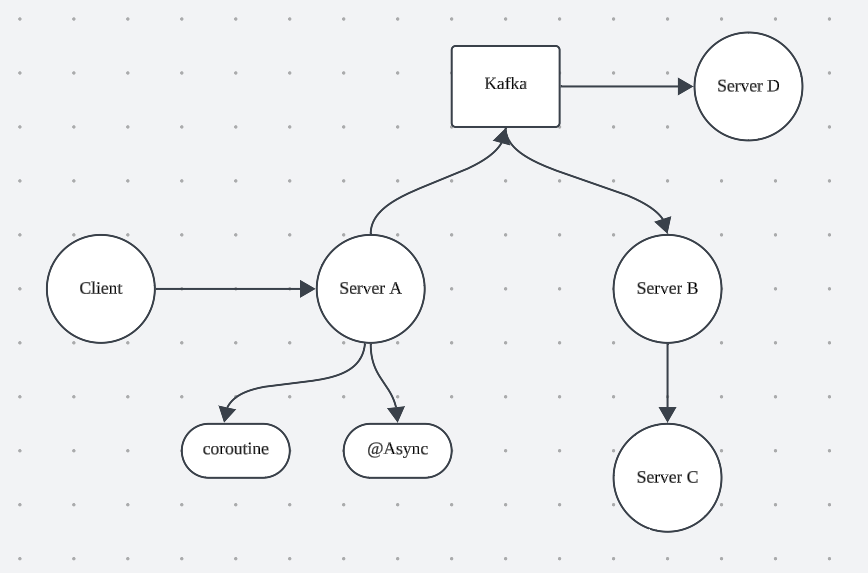
MSA 환경에서 Client가 하나의 호출을 수행했을 때 하나의 요청을 모아서 모니터링하고 싶으면 어떻게 해야 할까요?
아래 질문들에 대해 하나씩 답을 찾아가 보고자 합니다.
1. Server A에서 Spring MVC를 기반으로 여러 객체들이 협력하면서 비즈니스를 처리할텐데 어떻게 이어질 수 있을까?
2. Server A 에서 coroutine을 활용하면 어떻게 될까?
3. Server A 에서 @Async를 활용하면 어떻게 될까?
4. Server A가 kafka produce를 하고 Server B 가 consume을 수행하면 어떻게 될까?
5. Server B가 Server C에게 요청을 보낼 때는 어떻게 될까?
요청을 하나로 묶자
Spring MVC에서 여러 객체들이 협력하면서 비즈니스를 처리하는 상황을 떠올려 보겠습니다.
일반적인 Layered Architecture에서는 Controller, Service, Repository 구조로 객체가 구성되어 있고 비즈니스를 처리하는 것을 떠올릴 수 있습니다.
Spring MVC는 기본적으로 200개의 스레드로 구성되어 있으며, 하나의 요청당 하나의 스레드를 할당하여 처리합니다.
아래와 같이 logback을 구성해 보겠습니다.
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<logger name="test" level="INFO">
<appender-ref ref="STDOUT" />
</logger>
</configuration>
테스트를 위한 코드 구성
@RestController
class LoggingController(private val loggingService: LoggingService)
{
@GetMapping("/logging")
fun loggingController(){
testLogger.info("i am controller")
loggingService.loggingService()
}
}
@Service
class LoggingService{
fun loggingService(){
testLogger.info("i am service")
}
}
private val testLogger = LoggerFactory.getLogger("test")
요청 후 로깅 결과
22:16:47.404 [http-nio-8080-exec-1] INFO test - i am controller
22:16:47.406 [http-nio-8080-exec-1] INFO test - i am service
http-nio-8080-exec-1 이라는 스레드를 통하여 하나의 요청이 잘 처리됨을 확인할 수 있습니다.
하지만 유저가 1000명이 넘게 요청을 하게 된 경우 한 유저가 요청을 보냈다는 걸 어떻게 알 수 있을까요?
스레드가 200개라고 가정했을 때 현재 상태라면 평균적으로 5명의 유저가 같은 스레드를 활용하게 될 것입니다.
답은 traceId
userId 등의 유저 식별자를 로그에 같이 기록한다면 유저별로 기록할 수 있을 것 같습니다.
하지만 같은 유저가 여러 번 요청을 하고 같은 스레드를 활용하게 될 수도 있습니다.
따라서 userId 함께 UUID와 같이 요청 당 UNIQUE 한 값을 기록해 둔다면 여러 번 요청하는 경우도 해결할 수 있을 것 같습니다.
이런 값을 추척하기 위한 id인 traceId라고 부릅니다.
TraceId 직접 만들어서 넘겨보자
@GetMapping("/logging")
fun loggingController(){
val traceId = UUID.randomUUID().toString()
testLogger.info("i am controller traceId: $traceId")
loggingService.loggingService(traceId)
}
fun loggingService(traceId: String){
testLogger.info("i am service traceId: $traceId")
}UUID를 직접 만들어서 traceId로 선언한 뒤 Controller에서 활용합니다.
그리고 traceId를 Service로 넘겨서 다시 로깅에 활용합니다.
요청 후 로깅 결과
22:45:00.853 [http-nio-8080-exec-1] INFO test - i am controller traceId: 04808783-3f5e-442c-8321-4677ae7814c3
22:45:00.854 [http-nio-8080-exec-1] INFO test - i am service traceId: 04808783-3f5e-442c-8321-4677ae7814c3
스레드에 대한 정보도 잘 나오며, 이제 traceId에 대한 정보도 얻을 수 있습니다.
하지만 문제가 있습니다.
현재는 Controller, Service 두 컴포넌트만 협력하는데 만약 10개의 컴포넌트가 협력하여 로깅을 해야 한다면 어떨까요?
매번 traceId를 인자로 넘기는 귀찮은 작업을 해야 합니다.
하나의 요청은 하나의 스레드 - ThreadLocal
Spring MVC에서 기본적으로 하나의 요청은 하나의 스레드를 통해 해결된다는 점을 활용해 볼 수 있습니다.
Thread가 변수에 대해서 독립적으로 접근할 수 있는 기술인 ThreadLocal이라는 개념을 활용해 볼 수 있습니다.
Thread가 traceId를 로컬변수로 가진다면 함수를 호출할 때 인자를 넘기지 않고 활용할 수 있습니다.
ThreadLocal을 직접 구현할 수 있겠지만 slf4j의 MDC(Mapped Diagnostic Context)를 활용해 볼 수 있습니다.
MDC를 한국어로 풀이해 보면 진단을 위한 정보를 Key-Value 형태로 매핑하여 요청의 맥락을 추적하는 기능이라고 이해할 수 있습니다.
이때 MDC는 내부적으로 ThreadLocal 개념을 활용합니다.
Spring Filter와 MDC
@Component
@Order(Ordered.HIGHEST_PRECEDENCE)
class TraceIdFilter : Filter {
override fun doFilter(request: ServletRequest, response: ServletResponse, chain: FilterChain) {
try {
// 생성되신 nginx, client 에서 헤더로 넘겨주는 값을 세팅해도 OK
val traceId = UUID.randomUUID().toString()
MDC.put("traceId", traceId)
chain.doFilter(request, response)
} finally {
MDC.clear()
}
}
}
요청을 받는 앞단에서 UUID를 생성해 줍니다.
이때 Client가 보내주는 헤더등에서 값을 받아서 세팅해 줄 수도 있습니다.
이후 요청이 끝나면 MDC.clear() 를 통하여 traceId를 제거해주어야 합니다.
매번 새로운 스레드를 생성하지 않고 스레드 풀에서 꺼내서 활용하다 보니 반납하기 전에 적절하게 정리가 되어 있지 않으면 새로운 요청에서 스레드로컬에 남아 있던 값을 잘못 활용할 수 있습니다.
logback 세팅 추가
[%X{traceId}]
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>[%X{traceId}] %d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>[%X{Key}] 형식으로 MDC에 포함된 key를 자동으로 로깅에 넣어줄 수 있습니다.
요청 후 로깅 결과
[6ac27cca-dbab-48b1-a1ec-72abeeb953f6] 10:11:58.012 [http-nio-8080-exec-1] INFO test - i am controller traceId: 62b253bd-81bd-453e-883d-8e81db77de6c
[6ac27cca-dbab-48b1-a1ec-72abeeb953f6] 10:11:58.014 [http-nio-8080-exec-1] INFO test - i am service traceId: 62b253bd-81bd-453e-883d-8e81db77de6c로깅에 traceId가 잘 표현되는 것을 확인해 볼 수 있습니다.
Thread가 분리되면 어떻게 할까?
하나의 요청은 하나의 스레드가 처리한다는 전제에서는 문제가 없지만 하나의 요청을 여러 스레드에서 처리하게 되면 어떻게 될까요?
답은 요청을 처리하는 스레드에도 MDC Context를 전파해주어야 합니다.
coroutine, @Async, Kafka 등을 활용할 때는 어떻게 MDC Context를 전파해주어야 하는지 알아보겠습니다.
coroutine에서의 로깅
@Service
class CoroutineService {
fun coroutineLogging(){
CoroutineScope(Dispatchers.IO).launch {
testLogger.info("i am coroutine service 1")
delay(1000L)
testLogger.info("i am coroutine service 2")
}
CoroutineScope(Dispatchers.IO).launch {
delay(10)
testLogger.info("i am coroutine service 1")
testLogger.info("i am coroutine service 2")
}
}
}coroutine을 활용해서도 다양한 기능을 만들어낼 수 있습니다.
coroutine을 활용하게 되면 coroutine이 실행될 적절한 스레드풀을 만들게 될 것이고 별도의 스레드에서 실행됩니다.
delay를 통하여 코루틴 내부에서도 스레드의 이동이 가능하도록 구성해 보았습니다.
실제 로깅 결과를 보면 어떨까요?
요청 후 로깅 결과
[9f749020-1221-4e51-bd38-13558759d875] 11:01:23.985 [http-nio-8080-exec-1] INFO test - i am controller traceId: 3b50fa12-5999-4ed8-9032-c3bee0f1f250
[9f749020-1221-4e51-bd38-13558759d875] 11:01:23.986 [http-nio-8080-exec-1] INFO test - i am service traceId: 3b50fa12-5999-4ed8-9032-c3bee0f1f250
[9f749020-1221-4e51-bd38-13558759d875] 11:01:23.992 [taskExecutor-1] INFO test - i am async service
[] 11:01:24.049 [DefaultDispatcher-worker-1] INFO test - i am coroutine service 1
[] 11:01:24.076 [DefaultDispatcher-worker-3] INFO test - i am coroutine service 1
[] 11:01:24.076 [DefaultDispatcher-worker-3] INFO test - i am coroutine service 2
[] 11:01:25.063 [DefaultDispatcher-worker-3] INFO test - i am coroutine service 2coroutine을 활용한 Thread에서는 traceId를 알 수 없어 적절하게 로깅이 남지 않습니다.
2개의 woker를 활용한 모습을 확인할 수 있습니다. (worker-1, worker-3)
어떻게 해야 할까요?
coroutine에서는 kotlinx-coroutins-slf4j 라이브러리를 통하여 MDCContext() 라는 메서드를 제공합니다.
@Service
class CoroutineService {
fun coroutineLogging(){
CoroutineScope(Dispatchers.IO + MDCContext()).launch {
Thread.sleep(1000L)
testLogger.info("i am coroutine service")
}
}
}MDCContext()만 CoroutineContext로 넘겨주게 되면 기존 MDC가 잘 전파됩니다.

MDCContext()는 내부적으로 MDCContextMap을 프로퍼티로 가지며 MDC에서 값을 읽어오도록 구성되어 있습니다.
그런데 coroutine은 실행되다가도 다른 스레드로 이동되어 실행될 수 있습니다.
어떻게 이런 것이 가능할까요?

coroutine이 다른 스레드로 이동되기 전에 updateThreadContext가 호출됩니다.
이때 기존의 MDC를 전파합니다.
기존에 실행되던 스레드에는 clear()가 어떻게 될까에 대해서 잠깐 고민했지만, 새로운 코루틴이 스레드를 점유해서 실행될 때는 다시 updateThreadContext()가 호출될 테고 기존 스레드의 MDC Context로 다시 override 하게 되어 문제가 없습니다.
요청 후 로깅 결과
[e5b19c43-f1c3-4521-b83d-80cf0c34640f] 11:07:21.749 [http-nio-8080-exec-2] INFO test - i am controller traceId: c23d45cc-3e7e-477e-8d64-36166815c12d
[e5b19c43-f1c3-4521-b83d-80cf0c34640f] 11:07:21.749 [http-nio-8080-exec-2] INFO test - i am service traceId: c23d45cc-3e7e-477e-8d64-36166815c12d
[e5b19c43-f1c3-4521-b83d-80cf0c34640f] 11:07:21.750 [DefaultDispatcher-worker-1] INFO test - i am coroutine service 1
[e5b19c43-f1c3-4521-b83d-80cf0c34640f] 11:07:21.772 [DefaultDispatcher-worker-4] INFO test - i am coroutine service 1
[e5b19c43-f1c3-4521-b83d-80cf0c34640f] 11:07:21.772 [DefaultDispatcher-worker-4] INFO test - i am coroutine service 2
[e5b19c43-f1c3-4521-b83d-80cf0c34640f] 11:07:22.751 [DefaultDispatcher-worker-4] INFO test - i am coroutine service 2
@Async에서의 로깅
@Service
class AsyncService {
@Async
fun asyncLogging(){
testLogger.info("i am async service")
}
}Spring에서는 @Async를 활용하여 간편하게 비동기로 메서드를 처리할 수 있습니다.
하지만 @Async는 비동기로 메서드를 처리하기 위해 별도의 스레드에서 작업을 처리합니다.
실제 로깅 결과를 보면 어떨까요?
요청 후 로깅 결과
[e5b19c43-f1c3-4521-b83d-80cf0c34640f] 11:07:21.749 [http-nio-8080-exec-2] INFO test - i am controller traceId: c23d45cc-3e7e-477e-8d64-36166815c12d
[e5b19c43-f1c3-4521-b83d-80cf0c34640f] 11:07:21.749 [http-nio-8080-exec-2] INFO test - i am service traceId: c23d45cc-3e7e-477e-8d64-36166815c12d
[] 11:07:21.750 [taskExecutor-2] INFO test - i am async service
[e5b19c43-f1c3-4521-b83d-80cf0c34640f] 11:07:21.750 [DefaultDispatcher-worker-1] INFO test - i am coroutine service 1
[e5b19c43-f1c3-4521-b83d-80cf0c34640f] 11:07:21.772 [DefaultDispatcher-worker-4] INFO test - i am coroutine service 1
[e5b19c43-f1c3-4521-b83d-80cf0c34640f] 11:07:21.772 [DefaultDispatcher-worker-4] INFO test - i am coroutine service 2
[e5b19c43-f1c3-4521-b83d-80cf0c34640f] 11:07:22.751 [DefaultDispatcher-worker-4] INFO test - i am coroutine service 2@Async를 활용한 메서드에서는 traceId를 알 수 없어 적절하게 로깅이 남지 않습니다.
어떻게 해야 할까요?
스프링에선 TaskDecorator를 활용하여 비동기 작업이 수행되기 이전/이후의 작업을 데코레이트 할 수 있습니다.
이를 구현하여 비동기 작업이 수행되는 스레드에 MDC를 복제할 수 있다.
public class MdcTaskDecorator implements TaskDecorator {
@Override
public Runnable decorate(final Runnable runnable) {
final Map<String, String> copyOfContextMap = MDC.getCopyOfContextMap();
return () -> {
MDC.setContextMap(copyOfContextMap);
runnable.run();
};
}
}
@Configuration
@EnableAsync
public class AsyncConfig {
@Bean
public TaskExecutor taskExecutor() {
ThreadPoolTaskExecutor threadPoolTaskExecutor = new ThreadPoolTaskExecutor();
threadPoolTaskExecutor.setCorePoolSize(10);
threadPoolTaskExecutor.setTaskDecorator(new MdcTaskDecorator());
return threadPoolTaskExecutor;
}
}
TaskDecorator를 정의하는 MdcTaskDecorator를 정의합니다.
decorate 메서드는 MDC의 contextMap을 복제하여 스레드를 실행하기 전 넘겨줍니다.
AsyncConfig를 활용하여 TaskDecorator에 MdcTaskDecorator를 주입합니다.
이제 @Async가 활용될 때 MdsTaskDecorator에 의해 기존 MDC의 traceId가 전파될 수 있습니다.
요청 후 로깅 결과
[e5b19c43-f1c3-4521-b83d-80cf0c34640f] 11:07:21.749 [http-nio-8080-exec-2] INFO test - i am controller traceId: c23d45cc-3e7e-477e-8d64-36166815c12d
[e5b19c43-f1c3-4521-b83d-80cf0c34640f] 11:07:21.749 [http-nio-8080-exec-2] INFO test - i am service traceId: c23d45cc-3e7e-477e-8d64-36166815c12d
[e5b19c43-f1c3-4521-b83d-80cf0c34640f] 11:07:21.750 [taskExecutor-2] INFO test - i am async service
[e5b19c43-f1c3-4521-b83d-80cf0c34640f] 11:07:21.750 [DefaultDispatcher-worker-1] INFO test - i am coroutine service 1
[e5b19c43-f1c3-4521-b83d-80cf0c34640f] 11:07:21.772 [DefaultDispatcher-worker-4] INFO test - i am coroutine service 1
[e5b19c43-f1c3-4521-b83d-80cf0c34640f] 11:07:21.772 [DefaultDispatcher-worker-4] INFO test - i am coroutine service 2
[e5b19c43-f1c3-4521-b83d-80cf0c34640f] 11:07:22.751 [DefaultDispatcher-worker-4] INFO test - i am coroutine service 2
Kafka에서의 로깅
@Async, coroutine 은 하나의 서버에서 처리되는 스레드가 분리되었고, MDC 전파를 통해서 해결할 수 있었습니다.
kafka는 broker topic에 메시지가 저장되고 이 메시지를 여러 consumer가 처리하게 됩니다.
특정 서버가 전달할 kafka message를 어떻게 전달할 수 있을까요?
produce 할 때 traceId를 전달하고 consumer에서 traceId를 MDC로 수동으로 넣어주는 방식을 활용할 수 있습니다.
produce
public void sendMessageWithTraceId(String topic, String value) {
String traceId = MDC.get("traceId");
ProducerRecord<String, String> record = new ProducerRecord<>(topic, value);
record.headers().add("traceId", traceId.getBytes(StandardCharsets.UTF_8));
kafkaTemplate.send(record);
}
consume
@KafkaListener(topics = "yourTopic")
public void consume(ConsumerRecord<String, String> record) {
String traceId = new String(record.headers().lastHeader("traceId").value(), StandardCharsets.UTF_8);
MDC.put("traceId", traceId);
try {
// Process message
} finally {
MDC.clear(); // Clean up after processing
}
}
매번 produce, consume 하기 귀찮다면 Consume을 수행하는 AbstractClass 만들어서 래핑 하여 활용하거나 ProducerInterceptor, ConsumerInterceptor를 활용하여 MDC Context에서 값을 꺼내와서 전달하거나 매핑하는 작업을 수행해 줄 수 있습니다.
Client 호출에서의 로깅 - Feign
@Configuration
public class FeignConfig {
@Bean
public RequestInterceptor requestInterceptor() {
return requestTemplate -> {
String traceId = MDC.get("traceId");
if (traceId != null) {
requestTemplate.header("traceId", traceId);
}
};
}
}
RequestInterceptor를 활용하여 모든 Feign 요청을 가로채서 MDC Context에서 traceId를 가져와 세팅해 줄 수 있습니다.
받는 서버에서는 Filter를 활용하여 RequestHeader에서 traceId를 꺼내와서 MDC Context에 세팅해 줄 수 있습니다.
마무리
로깅에 대한 설정은 평소에 이미 구성되어 있고 그 설정을 따라 하기 때문에 지나치기 쉽습니다.
새로운 기술을 학습하는것도 좋지만 현재 구성된 시스템이 어떻게 연계되어 있는지 확인해볼 수 있어서 재미있었습니다.
이제 새로운 기술을 추가할 때는 운영 편의성을 위해 MDC Context에서 traceId를 전파할 수 있는지 고려해 볼 수 있을 것 같습니다.
참고자료
https://docs.spring.io/spring-kafka/reference/kafka/interceptors.html