spring kafka auto-commit 동작원리 : 데이터 유실과 중복처리
대상 독자
spring kafka의 auto-commit 동작원리를 알고 싶으신 분들
auto-commit을 활용할 때 데이터 유실과 중복처리를 제어할 수 있는 방법을 알고 싶으신 분들
개요
많은 블로그들을 살펴보면 kafka consumer의 옵션 중 하나인 auto-commit은 일정주기로 commit을 수행하기 때문에 메시지의 중복 및 유실이 발생할 수 있다고 설명합니다.
일정주기로 자동으로 commit을 수행한다는 것은 메시지가 처리되는 중간에도 commit이 일어날 수 있을 것 같습니다.
만약 auto-commit을 활성화한다면 내부적으로는 어떤 일이 일어날까요?
이번 글에서는 spring kafka에서 auto-commit이 어떻게 동작하는지 알아보고 이 과정에서 데이터 유실과 중복처리를 어떻게 제어할 수 있을지 알아보고자 합니다.
kafka producer와 consumer

consumer의 주요한 역할은 producer에 의해 발송되어 Kafka Broker의 topic에 저장되어 있는 메시지를 가져오는 역할을 수행합니다.
이때 auto-commit은 consumer에서 구성할 수 있는 옵션 중 하나입니다.
auto-commit이란?
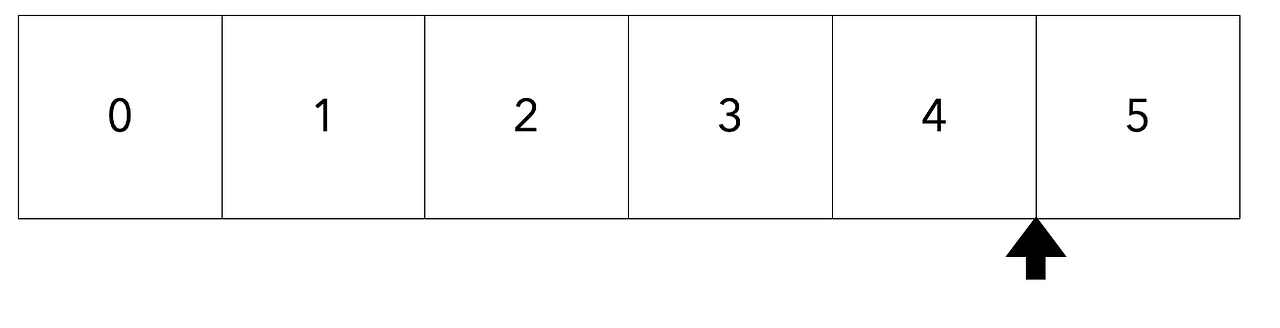
Consumer가 topic의 메시지를 가져올 때 offset이라는 개념을 활용합니다.
offset은 메시지를 어디까지 읽었는지를 저장하는 값이며 offset이 4라면 0, 1, 2, 3, 4 메시지를 읽은 것으로 생각할 수 있습니다.
예를 들어 Consumer가 메시지를 다시 읽기 시작하면 5라는 메시지를 가져오게 될 텐데 5라는 메시지를 읽었다고 다시 kafka broker에게 알려주는 과정이 commit입니다.
auto-commit은 commit 과정을 수동이 아닌 자동으로 수행하는 것을 뜻합니다.
만약 수동으로 commit 하는 방법이 궁금하신 분들은 kafka manual commit에 대해 알아보시면 좋을 것 같습니다.
auto-commit 자동이란 무엇일까?
수동은 무언가 메서드를 호출해 주면 commit이 kafka broker에게 전달될 것 같은데 자동이란 무엇일까요?
백그라운드 스레드에 의해 특정 주기로 commit이 수행되는 걸까요?
혹은 kafka broker가 내부적으로 처리해 주는 걸까요?
auto commit은 실제로 어떻게 동작하는지 테스트를 해보고 디버깅을 통해 spring-kafka의 내부로 들어가 보겠습니다.
spring-kafka 세팅
gradle spring-kafka의 의존성 추가
implementation("org.springframework.kafka:spring-kafka")글을 작성하는 시점에 활용한 spring-kafka의 버전은 3.0.7 kafka-client의 버전은 3.4.0입니다.
docker기반 kafka 환경 세팅
#docker-compose.yml
version: '2'
services:
zookeeper:
container_name: local-zookeeper
image: wurstmeister/zookeeper
ports:
- "2181:2181"
kafka:
container_name: local-kafka
image: wurstmeister/kafka
depends_on:
- zookeeper
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1
KAFKA_ADVERTISED_PORT: 9092
KAFKA_CREATE_TOPICS: "test:1:1" #topic이름:partition개수:replica개수
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
- /var/run/docker.sock:/var/run/docker.sock
kafka 정보를 얻기 위해 container로 접근
예시)
docker exec -it <컨테이너 ID> /bin/bash
실제)
docker exec -it b938b57cb74a /bin/bash
container Id 조회방법)
docker ps
어떤 topic이 존재하는지 확인
kafka-topics.sh --bootstrap-server localhost:9092 --list
현재 존재하는 consumer group 찾기
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list
특정 consumer group의 offset commit 값 확인
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group test --describetest라는 이름을 가진 consumer group의 offset을 확인해 볼 수 있습니다.
특정 consumer group 삭제
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --delete --group testconsumer 구동 후 재 테스트를 위해 test consumer group을 삭제하는 예시입니다.
spring-kafka auto-commit 테스트
test topic에 10개 메시지를 발행한 뒤 max.poll.records를 10으로 세팅하여 한번 poll() 메서드를 호출할 때 10개의 메시지를 읽어보겠습니다.
@Component
class KafkaConsumer{
val logger = KotlinLogging.logger{}
@KafkaListener(topics = ["test"], groupId = "test" ,containerFactory = "myContainerFactory")
fun consume(payload: TestDto) {
logger.info("Consumer start: $payload")
sleep(1000)
logger.info("Consumer end: $payload")
}
}
이때 각 메시지는 처리하는데 1초가 걸린다고 가정했을 때 auto-commit을 2초로 세팅하고 3초 뒤 offset은 어떻게 되어있을까요?

test라는 이름을 가진 consumer group의 current-offset을 살펴보면 2초마다 2개씩 offset이 commit 되지 않고 한 번에 10개의 commit이 반영된 것을 확인할 수 있습니다.
spring-kafka 내부적으로는 어떤 일이 일어나고 있을까요?
spring-kafka auto-commit 내부 속으로
spring-kafka가 consume 하는 로직에 디버깅포인트를 찍고 들어가 보겠습니다.

KafkaMessageListenerContainer의 run() 메서드에서 pollAndInvoke() 메서드를 호출합니다.
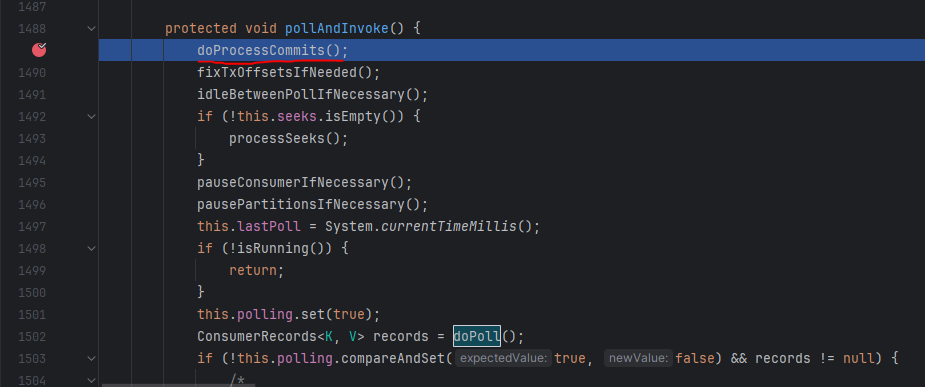
pollAndInvoke() 메서드에서는 내부적으로 doPorcessCommits 메서드를 호출합니다.

autoCommit이 false이며 recordAck가 false인 경우에는 processCommits() 메서드를 수행합니다.
현재는 autoCommit이 true이므로 조건문에 해당하지 않습니다.
autoCommit이 false 라도 Record 방식의 Ack를 활용하지 않는다면 processCommits() 메서드를 수행하지 않습니다.

doProcessCommits에서는 조건에 만족하지 않아 별다른 처리가 일어나지 않았고 아래의 doPoll()을 호출합니다.

pollConsumer() 메서드를 통해 10개의 records를 가져옵니다.

invokeIfHaveRecods 메서드를 통해 10개의 recoreds를 인자로 넘겨 실행합니다.
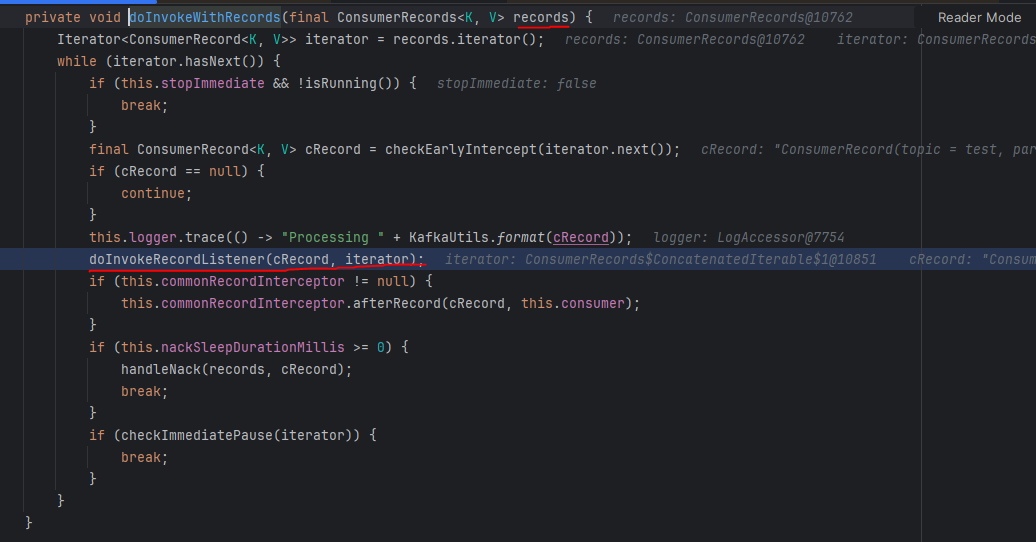
doInvokeWithRecords 메서드에서 반복문을 통하여 doInvokeRecordListener를 호출합니다.
10개의 records를 순회하면서 인자로 넘기는 cRecord는 각각 한 개의 메시지입니다.

이후에는 invokeOnMessage 메서드를 통해 개별 메시지의 처리가 doInvokeOnMessage() 메서드에 의해 이루어집니다.
메시지를 처리한뒤에는 ackCurrent를 통해 현재 메시지를 commit 하려고 시도합니다.
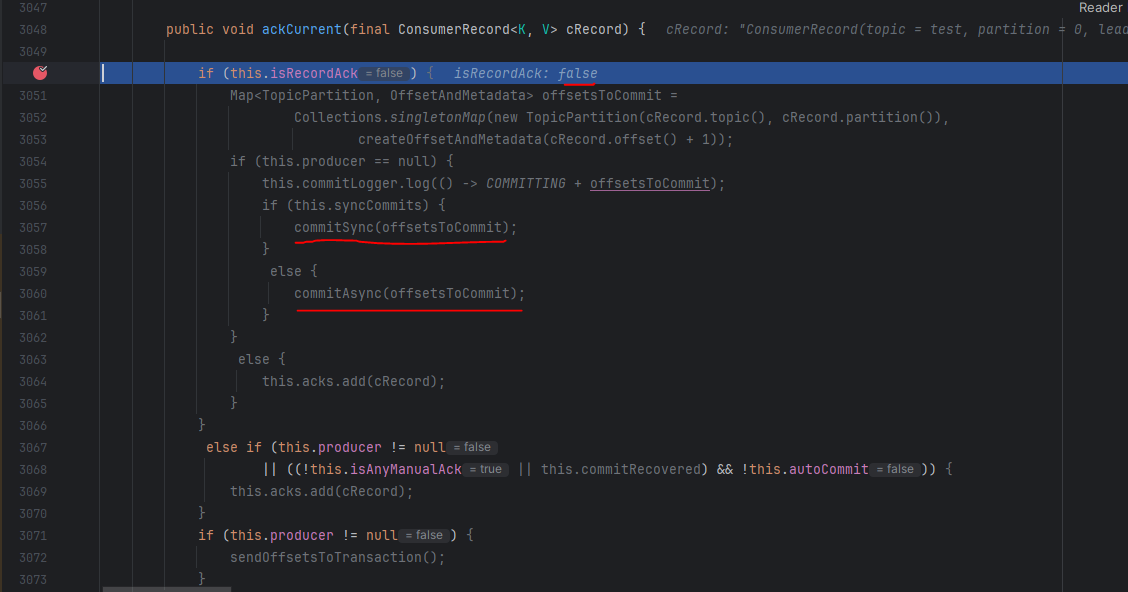
하지만 record 방식의 commit이 아니라면 commitSync(), commitAsync() 메서드는 호출되지 않습니다.

10개의 메시지가 모두 처리된 후 다시 메시지를 가져오기 위해 doPoll() 메서드를 호출합니다.
이때 current-offset은 아무 내용이 없습니다. (CURRENT-OFFSET이 " - " 로 확인)

kafkaConsumer의 poll 메서드 내부에는 updateAssignmentMetadataIfNeeded()를 호출하고 있습니다.

조금 더 내부로 들어가면 ConsumerCoordinator 클래스의 maybeAutoCommitOffsetsAsync 메서드에 의해 autoCommitOffsetAsnyc() 메서드가 호출됩니다.
이때 autoCommitIntervalMs가 지났는지 검사하고 시간이 지났다면 reset을 통해 새롭게 다음에 일어날 autoCommit 시간을 세팅합니다.

autoCommitOffsetAsnyc() 메서드를 살펴보면 실제 commit이 일어나고 test-0 토픽에 offset을 10으로 세팅하는 모습을 볼 수 있습니다.

결론적으로 요약해 보자면 poll() 메서드가 호출될 때 autoCommit에 설정된 시간만큼이 지났는지 확인하고 시간이 지났으며 commit 할 내용들이 있으면 commit을 진행하게 됩니다.
따라서 처음 poll() 메서드가 호출되었을 때는 10개의 메시지를 가져와서 처리하고, 다음 메시지를 들고 오는 과정에서 autoCommit이 발생하게 됩니다.
즉, 10개의 메시지를 처리하는 시간이 10초이고 autoCommit의 시간이 2초라면 2초 뒤에 commit이 일어나지 않으며 메시지가 모두 처리된 10초 뒤에 다음 poll() 메서드에 의해 commit이 발생하게 되면서 메시지는 유실되지 않습니다.
예외적인 상황도 고려해볼 수 있습니다. 만약 설정된 session.timeout.ms 동안 하트비트를 수신하지 못하거나 설정된 max.poll.interval.ms 동안 poll() 호출 하지 못하게 되면 consumer가 문제가 있다고 판단되어 할당된 파티션을 빼앗기게되는 리밸런싱이 발생하게 됩니다.
이때 poll() 하게 되는 메시지의 개수가 많거나 autoCommit 주기가 길게 되면 그만큼 더 많은 중복 메시지를 처리하게 됩니다.
예를 들어 500개의 메시지를 poll() 하게 되면 500 개의 중복 처리가 발생할 수 있지만, 5개의 메시지를 poll() 하도록 설정되어 있다면 5개의 중복 처리가 발생할 수 있습니다.
리밸런싱에 대해 조금 더 자세하게 알고 싶으신 분들은 11번가의 기술블로그인 카프카 컨슈머 애플리케이션 배포 전략 글을 참고해주세요. 개인적으로 리밸런싱과 관련된 글 중 가장 잘 이해가 되었습니다.
리밸런싱 이외에도 poll()을 수행하고 메시지를 처리하던 중 application crash(비 정상적인 서버 종료)가 발생하더라도 다음 poll()을 통해 commit이 수행되기 때문에 다음 poll()을 호출하지 못할 것이며 메시지는 유실되지 않습니다.
한줄로 정리하자면 메시지 중복은 발생할 수 있으나, 유실은 발생하지 않습니다.
autoCommit과 별개의 문제로 N회 retry 하고도 메시지가 처리되지 않는다면 특정 메시지를 무한으로 재처리할 수 없으니 다음 메시지를 처리하면서 유실될 가능성은 존재합니다.
중복처리
중복처리를 최소화하기 위해서는 한 번에 메시지를 가져오는 옵션의 개수인 max.poll.records를 1로 제어하고 autoCommit 주기를 짧게 가져가볼 수 있습니다.
그럼에도 불구하고 1건의 메시지에 대해서는 중복처리가 발생할 수 있습니다.
이런 중복처리를 대비하여 consumer의 application 로직을 작성할 때는 같은 메시지가 N번 들어와도 동일한 결과를 나타낼 수 있도록 멱등성 있도록 구현할 수 있습니다.
예를 들어 A 메시지가 들어왔다면 DB에 A 메시지가 들어옴을 key나 id를 기반으로 저장해 두고, A 메시지가 중복 수신된 경우에는 return 하는 식으로 처리해 볼 수 있습니다.
마무리
평소에 이론으로만 auto commit에 대해 인지하고 auto commit 옵션을 활용하고 application이 crash 되었을 때 유실될 수 있다고 생각하고 있었습니다.
하지만 실제 spring-kafka의 로직을 보면 application이 중간에 crash 되었을 때 일정시간이 지났을 때 백그라운드로 commit을 수행하지 않고 다음 poll()을 수행하지 않으면 commit을 수행하지 않으므로 중복처리는 발생할 수 있지만 유실은 발생하지 않습니다.
항상 당연하게 생각했던 것에 의문을 가지면서 접근하는 것이 새로운 인사이트를 주는 것 같습니다.
참고자료
https://www.baeldung.com/kafka-commit-offsets
https://simsim231.tistory.com/293
https://firststep-de.tistory.com/41
https://hanseom.tistory.com/174
https://piotrminkowski.com/2024/03/11/kafka-offset-with-spring-boot/
https://dzone.com/articles/preventing-data-loss-with-kafka-listeners-in-sprin
https://stackoverflow.com/questions/46546489/how-does-kafka-consumer-auto-commit-work
https://www.nasa1515.com/apache-kafka-consumer-poll-method-offset-commit/#-kafka-consumer