-
RDBMS와 NoSQL 정리(+ 차이점, 언제 무엇을 사용해야 할까)CS/데이터베이스 2022. 1. 16. 00:01반응형
RDBMS란?
RDBMS란(Relational DataBase Management System)의 약자로 관계형 데이터베이스를 수정하고 관리할 수 있는 소프트웨어입니다.
관계형 데이터베이스란 무엇일까요?
데이터를 열(Column)과 행(row)으로 구성하여 하나 이상의 테이블로 정리하며 고유 키(Primary key)가 각 행(row)을 식별합니다.
또한 이러한 테이블끼리 서로 연관되어 있어 효율적으로 데이터를 저장, 구성 및 관리할 수 있습니다.
또한 사용자가 관계형 데이터 베이스를 사용하기 위해 표준 검색 언어인 SQL을 사용하여 데이터를 조회, 수정 등을 할 수 있습니다.
MSSQL, MySQL, Oracle이 RDBMS의 몇 가지 예시입니다.

학생 릴레이션 위의 그림은 관계형 데이터베이스의 학생 릴레이션의 예시입니다.
속성(Attribute) 학번, 이름, 학년, 신장, 학과 등은 하나의 열(Column)에 해당된다.
이를 릴레이션 스키마라 부릅니다.
튜블(Tuple)은 속성에 대한 값들로 채워지게 되며 하나의 행(row)에 해당됩니다.
데이터를 속성(열)과 튜플(행)을 통해 학생 테이블로 정리하였습니다.
위에서 고유 키(Primary key)를 통해 각 행(row)을 식별한다고 했는데 Primary key란 무엇일까요?
Primary Key란?
학번, 주민등록번호와 같이 고윳값을 가지는 속성을 의미합니다.
예를 들면 학생 테이블의 속성인 신장, 이름, 학년, 학과 등은 다른 사람과 같은 값을 가질 수 있습니다.
신장이 같을 수도 있고, 이름이 같을 수도 있고, 학년이 같을 수도 있고, 학과가 같을 수도 있습니다.
하지만 주민등록번호나 학번이 같은 사람이 존재하지는 않습니다.
이처럼 고윳값을 가지는 속성 중 하나를 선택하여 Primary Key를 선택하며 고윳값을 가지므로 이를 통해 각 튜플(행)들을 식별할 수 있습니다.
릴레이션 스키마와 인스턴스란?
스키마는 데이터베이스의 릴레이션이 어떻게 구성되는지 어떤 정보를 담고 있는지에 대한 기본적인 구조를 정의합니다.
인스턴스는 정의된 스키마에 따라 테이블에 실제로 저장되는 데이터의 집합을 의미합니다.
릴레이션과 테이블의 차이점
위의 그림은 학생 릴레이션, 학생 테이블 등으로 불립니다.
우선 바로 말하자면 릴레이션은 모두 테이블이지만 모든 테이블은 릴레이션이 아닙니다.
릴레이션이 조금 더 큰 개념이라는 의미입니다.
릴레이션은 다음의 조건을 만족해야 합니다.
- 행은 개체에 대한 데이터를 포함한다.
- 열은 개체의 속성에 대한 데이터를 포함한다.
- 한 열의 모든 항목은 동일한 종류이다.
- 각 열은 유일한 이름을 가진다.
- 테이블의 셀은 단일 값을 포함한다.
- 열의 순서는 중요하지 않다.
- 행의 순서는 중요하지 않다.
- 어떤 두 개의 행도 동일하지 않다.
그러면 아래의 그림들을 살펴보면서 테이블과 릴레이션을 구분해 보겠습니다.

릴레이션 x 위의 그림은 사원번호 300번을 가진 오돌이의 행이 두 번 반복해서 나오는 모습입니다.
따라서 위의 그림은 테이블이지만 릴레이션은 아닙니다.

릴레이션 x 위의 그림은 "테이블의 셀은 단일 값을 포함한다"을 위반하였습니다.
따라서 위의 그림은 테이블이지만 릴레이션은 아닙니다.
NoSQL이란?
어떤 사람은 NoSQL을 "non SQL"의 약자로, 또 누군가는 "non only SQL"의 약자로 생각합니다.
어떤 경우든 NoSQL 데이터베이스가 관계형 데이터베이스 이외의 형식으로 데이터를 저장합니다.
흔히 NoSQL 데이터베이스는 관계 데이터를 저장하지 않는다고 오해하지만 관계 데이터를 저장할 수 있습니다.
데이터가 정형, 반정형, 다형적 등 모양과 크기가 모두 다르기 때문에 미리 스키마를 정의하는 것이 힘들어졌고 NoSQL을 사용하여 개발자가 엄청난 양의 비정형 데이터를 저장할 수 있도록 지원합니다.
MongoDB, Amazon DynamoDB가 NoSQL의 예시입니다.
NoSQL의 이론적 배경, CAP Theorem

https://12bme.tistory.com/615 대용량 분산 데이터 저장소는 일관성(Consistency), 가용성(Availability), 단절 내성(Partition Tolerance)을 모두 만족시키는 것은 불가능하며 두 가지만 전략적으로 선택해야 한다는 이론입니다.
일관성 모든 요청은 최신 데이터 또는 에러를 응답받는다. 가용성 모든 요청은 정상 응답을 받는다. 파티션 허용성 노드간 통신이 실패하는 경우라도 시스템은 정상 동작 한다 여기서 말하는 일관성은 ACID의 일관성과는 다릅니다.
ACID의 일관성은 DB의 트랜잭션이 완료되었을 때 기존의 제약을 위반하지 않아야 함을 의미합니다.
세 가지 속성 중 2가지를 만족하는 시스템은 CA, CP, AP 세 종류로 나눌 수 있습니다.
하지만 대용량 분산 데이터를 저장하기 위해서는 노드 간 통신이 실패하는 경우라도 시스템은 정상 동작해야 하기 때문에 CA 시스템은 존재할 수 없습니다. (또한 네트워크 장애가 절대 일어나지 않는 네트워크 구성은 존재할 수 없습니다.)
CAP이론의 한계
분산 시스템의 성질을 단순 명료하게 설명해주는 만큼 한계를 가집니다.
분산 시스템은 항상 CP 또는 AP여야 합니다.
완벽한 CP 시스템
완벽한 일관성을 갖는 분산 시스템에서는 하나의 트랜잭션이 다른 모든 노드에 복제된 후에 완료될 수 있습니다. 이는 가용성뿐만 아니라 성능의 희생도 필요합니다.(지연시간의 증가)
완벽한 AP 시스템
완벽한 가용성을 가지는 시스템은 모든 노드가 어떤 상황에서라도 응답할 수 있어야 합니다.
만약 하나의 노드가 네트워크 파티션으로 인해 고립되었다면 해당 데이터는 일관성이 깨지기 때문에 쓸모 없어지지만 응답한다면 어쨌든 완벽한 가용성을 갖게 됩니다. 하지만 해당 노드를 사용하는 사용자는 문제를 인지하지 못하고 계속 요청을 보낼 수 있습니다.
더 나은 CAP 이론의 해석은 "따라서 일관성과 가용성은 상충 관계에 놓여있지만 둘 중 반드시 하나를 선택해야 하는 것은 아니다"입니다.

http://happinessoncode.com/2017/07/29/cap-theorem-and-pacelc-theorem/ PACELC 이론
CAP 이론의 단점들을 보완하기 위해 나온 네트워크 장애 상황과 정상 상황으로 나누어서 설명하는 이론입니다.
P(네트워크 파티션) 상황에서 A(가용성)과 C(일관성)의 상충관계 E(else, 정상) 상황에서 L(지연 시간)과 C(일관성)의 상충 관계를 설명합니다.
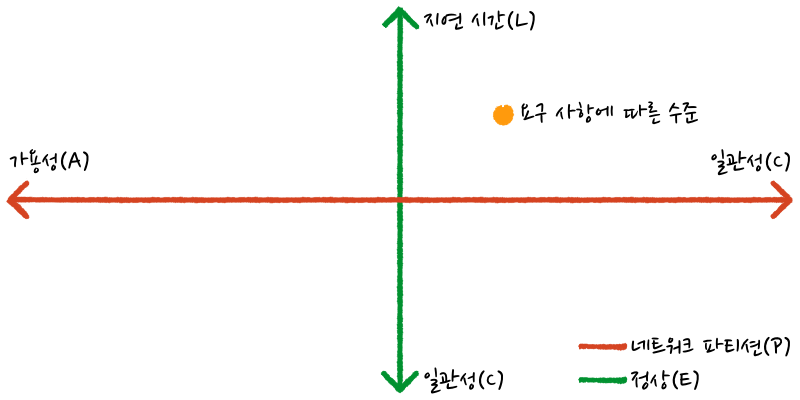
http://happinessoncode.com/2017/07/29/cap-theorem-and-pacelc-theorem/ 이때 지연 시간은 y축으로 올라갈 수록 지연시간이 짧아짐을 의미합니다.
ACID와 BASE
ACID
- Atomic - 각 트랜잭션이 제대로 수행되거나 또는 오류가 발생한 경우에는 트렌젝션이 시작되기 전의 상태로 되돌아갑니다. 이렇게 하면 데이터베이스의 모든 데이터가 유효합니다.
- Consistent - 처리된 트랜잭션은 데이터베이스의 무결성을 위협하지 않습니다.
- Isolated - 트랜잭션은 아직 진행 중인 동안 다른 트랜잭션과 상호 작용하여 다른 트랜잭션의 무결성을 손상시킬 수 없습니다.
- Durable - 완료된 거래와 관련된 데이터는 네트워크 또는 정전 시에도 유지됩니다. 트랜잭션이 실패하면 조작된 데이터에 영향을 미치지 않습니다.
한 계정에서 돈이 인출되고 오류로 인해 다른 계정으로 입금되지 않는다면 심각한 문제가 발생할 수 있기 때문에 금융 기관은 거의 독점적으로 ACID 데이터베이스를 사용합니다.
대부분의 관계형 데이터베이스 MySQL, PostgreSQL, Oracle, SQLite 등이 ACID를 지원합니다.
단, 일부 NoSQL도 ACID를 지원하기도 합니다.
BASE
- Basically Available - 데이터는 항상 접근 가능하다. (부분적인 고장은 있을 수 있으나, 나머지는 사용이 가능하다)
- Soft State - 노드의 상태는 외부에서 전송된 정보를 통해 결정된다.(정보를 새로 고치지 않으면 정보가 만료됨) 하지만 NoSQL 저장소는 실제로 이러한 방식으로 데이터를 새로 고칠 필요는 없습니다. Soft State로 저장된 값은 최신이 아닐 수 있지만 근삿값에 유용합니다.
- Eventually Consistent - 즉각적인 일관성을 적용하지는 못할 수 있지만 최종적으로는 일관성을 지원합니다.
사실 ACID(산) 과 대칭되는 의미를 가지는 BASE(염기)의 약자로써 사용하기 위해 끼워 맞춘 느낌이 강하게 듭니다.
감정 분석을 다루는 마케팅 및 고객 서비스 회사는 소셜 네트워크 조사를 수행할 때 BASE 데이터베이스를 선호합니다.
대부분의 NoSQL 데이터베이스 MongoDB, Cassandra, Redis, DynamoDB 등이 BASE 원칙을 따르는 경향이 있습니다.
ACID vs BASE 결론
프로젝트의 모든 측면을 고려하여 데이터베이스 모델을 결정해야 합니다.
일관성, 예측 가능성 및 안정성이 필요하다면 ACID가 적합합니다.
확장성과 유연성이 필요하다면 BASE가 적합합니다.
저장되는 데이터의 구조에 따라 아래와 같이 나누어 볼 수 있습니다.
1) Key-Value DB
각 항목에 키와 값이 포함되어 있는 유형의 데이터베이스입니다.
값은 보통 키를 참조하는 방식으로만 검색이 가능하기 때문에 특정 키-값 쌍에 대해 쿼리를 수행하는 방법을 간단히 익힐 수 있습니다.
키에 대한 접근은 빠르지만 범위 검색에 대해서는 취약합니다. (Hash Set과 유사하다고 생각합니다.)
복잡한 조회 연산을 지원하지 않기 때문에 고속 읽기와 쓰기에 최적화되어있습니다.
따라서 데이터를 In-Memory(RAM)에 저장하여 데이터를 빠르게 가져올 때 많이 사용됩니다.
대량의 데이터를 저장해야 하지만 검색을 위해 복잡한 쿼리를 수행할 필요가 없는 사용 사례에 적합합니다.
적절한 사용처
사용자의 프로필 정보, 웹서버의 클러스터를 위한 세션 정보, 장바구니 정보, url 단축 정보 저장 등이 해당됩니다.
해당 예제들은 모두 단일 연산에 의하여 처리를 완료하거나 취소할 수 있기 때문입니다.

Key-Value DB 예시 2) Wide Column Store DB
행 및 열에 데이터를 저장합니다.
각 행이 동일한 열을 가질 필요가 없다는 점에서 관계형 데이터베이스와는 달리 뛰어난 유연성을 제공합니다.
대표적인 DB로는 Cassandra, Hbase 등이 있습니다.
대부분의 칼럼 모델 NoSQL은 쓰기와 읽기 중에 쓰기에 더 특화되어 있습니다.
예를 들어 채팅 내용 저장, 메일 저장소, 알림 내용 저장, 실시간 분석을 위한 데이터 저장소 등의 서비스 구현에 적합합니다.
보통 사물 인터넷 데이터와 사용자 프로필 데이터를 저장하는 데 사용됩니다.

Wide Column Store DB 예시 3) Document DB
JSON 객체와 비슷한 문서에 데이터를 저장합니다.
각 문서에는 필드와 값의 쌍이 포함되어 있습니다.
Key-Value DB를 개념적으로 확장한 구조로 이해할 수 있습니다.
따라서 Document DB와 Key-Value DB는 경계가 모호한 경우도 존재합니다.
문서 모델은 하나의 키에 하나의 구조화된 문서를 저장하고 조회합니다.
일반적으로 값은 String, Number, boolean, Array, Obejct 등 다양한 유형을 가지며 구조는 개발자가 코드에서 사용하고 있는 객체에 맞춰 조정됩니다.

Document DB 예시 관계형 데이터베이스는 위와 같은 데이터를 저장하기 위해 first와 last 칼럼을 정의하고 null 값을 넣어야 하지만 문서 모델 NoSQL은 항상 고정된 필드를 가진 구조의 문서를 저장할 필요가 없습니다.
문서 모델 NoSQL에서 데이터에 대한 검색을 시도할 때, 조회 조건에 지정된 필드가 존재하지 않는 문서는 조회 대상에서 포함되지 않습니다.
대표적인 DB로는 Elasticsearch, MongoDB 등이 있으며 가장 인기 있는 Document DB입니다.
각 콘텐츠에 대해 정보를 관리하거나 카탈로그 같은 것을 저장할 때 효과적입니다.
자주 변하지 않는 정보를 저장하고 조회하는데 적합합니다.
예를 들어 로그 저장, 타임라인 저장, 통계 정보 저장 등이 이에 해당됩니다.
조회 시 특정 수량을 기준으로 잘라서 조회하는 기능 등에는 알맞지 않습니다.
대표적인 DB로는 Elasticsearch, MongoDB 등이 있으며 가장 인기 있는 Document DB입니다.
4) Graph DB
정점(Node)과 간선(Edge)에 데이터를 저장합니다. 정점(Node)에는 일반적으로 객체에 대한 정보가 저장되고, 간선(Edge)에는 정점 간의 관계에 대한 정보가 저장됩니다.
소셜 네트워크 및 추천 엔진에서 자주 사용됩니다.

Graph DB 예시 RDBMS와 NoSQL에 대해서 알아보았습니다.
그러면 주요 차이점에 대해 정리해 보겠습니다.
RDBMS NoSQL 데이터 저장 모델 고정된 행과 열이 있는 테이블 다양한 데이터 구조를 가짐 역사 데이터 중복 감소에 중점을 두고 1970년대에 개발됨 2000년대 후반에 확장에 중점을 두고 비정형 데이터들을 다루기 위해 등장 예시 Oracle, MySQL, Microsoft SQL Server MongoDB, Redis, DynamoDB 스케일링 수직적 확장(CPU 업그레이드)/ Sacle-up 수평적 확장(더 많은 서버 추가) / Sacle out 다중 레코드 ACID 트랜잭션 지원 대부분은 지원하지 않으나 일부는 지원 왜 NoSQL이 RDBS보다 확장성이 높을까?
보통 "확장을 한다"라고 말을 하면 2가지로 분류합니다.
Scale-up = 하드웨어의 업그레이드를 통한 수직적인 확장
Scale-out = 샤딩을 통한 수평적인 확장
Scale-up = 하드웨어를 업그레이드하는 것은 한계가 존재합니다.
Scale-out = 하드웨어를 업그레이드하지 않고 동일한 성능의 DB를 추가하는 것에는 한계가 존재하지 않습니다.
즉, NoSQL은 샤딩을 통한 수평적인 확장에 유리합니다.
RDBS는 샤딩이 불가능한 것은 아니지만 까다롭습니다.
이러한 이유는 join에서 나옵니다.
RDBS는 join을 할 수 있으며, NoSQL은 join을 할 수 없습니다.
RDBS는 각 테이블을 연관 짓는 것이 특징인데 테이블 1은 DB1에 존재하고 테이블 2는 DB2에 존재한다면 이를 join 하기 어렵습니다.
NoSQL은 join 할 필요가 없기 때문에 여러 서버의 행을 결합하는 것에 대해 걱정할 필요 없이 다른 서버에 있을 수 있습니다.
RDBMS는 언제 사용하면 좋을까?
특별한 이유가 존재하지 않는다면 RDBMS를 사용하면 됩니다.
- 변경될 여지가 없고, 명확한 스키마가 사용자와 데이터에게 중요한 경우
- 관계를 맺고 있는 데이터가 자주 변경되는 애플리케이션 ( NoSQL은 여러 컬렉션을 모두 수정해야 함)
- 각 데이터가 중복 없이 한 번만 저장되고 ACID 트랜잭션을 지원하여 무결성이 보장됨
NoSQL은 언제 사용하면 좋을까?
특별한 이유가 존재한다면 NoSQL을 고려해볼 만합니다.
- 정확한 데이터 구조를 알 수 없거나 확장될 수 있는 경우
- 데이터 읽기를 자주 하지만 변경을 자주 하지 않는 경우
- 데이터베이스를 수평으로 확장해야 하는 경우
또한 어떤 NoSQL을 사용할지 정하는 것도 매우 중요합니다.
고려해야 할 사항들
- 일관성 모델
- 서비스를 구현하기 위해 강한 일관성이 필요한지 먼저 확인해야 합니다. 강한 일관성이 필요한 서비스를 위해서 NoSQL을 선택하는 것은 득 보다 실이 클 수 있습니다.
- 데이터 모델
- 제공하려는 기능이 키-값 모델과 같은 간단한 데이터 모델로 처리가 가능한지 또는 문서 모델과 같이 중첩된 구조를 지원해야 하는지 판단해야 하는데 이 부분은 실제 구현에 따라 달라질 수 있습니다. 즉, 선택한 NoSQL의 데이터 모델로 필요한 기능을 구현할 수 있는지 판단해야 합니다.
- 읽기 쓰기 성능
- 제공할 기능의 읽기와 쓰기 비율에 따라서 선택할 NoSQL도 바뀌게 되어야 합니다. 예를 들어 읽기 쓰기 모두 빠른 응답 시간이 필요하다면 NoSQL이 후보가 될 수 있으며, 상대적으로 읽기 비율이 높다면 B트리 인덱스 구조를 사용하는 문서 모델 NoSQL이 후보가 될 수 있습니다.
- 단일 고장점
- 단일 고장점이란 어떤 시스템이 동작하지 않으면 전체 시스템이 중단됨을 의미합니다. 선택한 NoSQL이 단일 고장점을 가지고 있는지 확인해야 하며, 단일 고장점을 가지고 있더라도 쉬운 복구가 가능한지를 확인해야 합니다. 예를 들어, HBASE는 단일 고장점을 가지고 있지만 하드웨어적인 방법을 통해서 단일 고장점을 제거할 수 있습니다. 만약, 무정지 서비스가 중요 목표라면 단일 고장점을 가진 NoSQL 선택을 피해야 합니다.
- 원자성 지원
- 선택한 NoSQL의 트랜잭션 지원 여부, 단일 연산에 대한 원자성 지원 여부와 같은 CAP 특징을 확인해야 합니다. 원자성의 지원이 클라이언트/서버 어느 쪽에서 지원되는지 확인해야 합니다. 만약 클라이언트에서 지원한다면 코드의 복잡성을 증가시킬 수 있습니다.
- 하드웨어 구성
- 해당 NoSQL이 가지는 시스템 아키텍처를 확인해야 합니다. 가용성을 지원하기 위해서 Master-Slave 구조를 선택했다면 저장되는 데이터의 최대 크기는 절대적인 저장소 크기의 절반입니다. 또한 NoSQL 내부의 구성요소와 하드웨어에 대한 기본 구성 정보를 알아야 합니다. 예를 들어 HBASE는 최소 5대 이상의 하드웨어에서 수행되어야만 성능의 선형 증가를 얻을 수 있습니다.
- 무중단 시스템
- 시스템을 확장할 때 시스템 중단이 필요한지 여부와 같은 시스템의 특정을 확인해야 합니다. 예를 들면 MongoDB와 같이 자동 샤딩을 지원하는 NoSQL은 운영 중에 시스템을 추가할 수 있지만, 자동 샤딩 중에는 서비스 응답 시간이 느려지기도 합니다.
결론
위와 같은 고려사항을 확인하여 서비스에서 필요한 부분과 필요 없는 부분을 먼저 선택하고 난 뒤 그에 맞는 NoSQL을 선택해야 합니다.
즉, 필요한 요구 사항을 모두 만족하는 NoSQL을 선택해야 합니다.
일반적으로 서비스 구현은 한 가지 NoSQL만을 사용하여 모든 서비스를 제공하도록 구성하지 않습니다.
서비스를 부분으로 나누어 별도의 NoSQL을 배치하고 주 저장소는 RDBMS를 사용하기도 합니다.
출처
관계형 데이터베이스 - 위키백과, 우리 모두의 백과사전
관계형 데이터베이스(關係形 Database, Relational Database, 문화어: 관계자료기지, 관계형자료기지, RDB)는 키(key)와 값(value)들의 간단한 관계를 테이블화 시킨 매우 간단한 원칙의 전산정보 데이터베이
ko.wikipedia.org
Relation과 Table의 차이
데이터베이스 관련 책을 읽다보면 Relation과 Table을 같은 용어로 이야기하는 경우가 있다. 어떤 책의 경우 "릴레이션이 테이블이다." 라고 되어있다. 하지만 사실상 릴레이션은 테이블과는 약간
5dol.tistory.com
파일:릴레이션 구조.png - 해시넷
날짜/시간 링크를 클릭하면 해당 시간의 파일을 볼 수 있습니다. 날짜/시간섬네일크기사용자댓글 현재2020년 8월 5일 (수) 14:13773 × 239 (47 KB)theraker (토론 | 기여) 다음 문서 1개가 이 파일을 가리키
wiki.hash.kr
https://upload.wikimedia.org/wikipedia/commons/5/5b/KeyValue.PNG
https://aws.amazon.com/ko/nosql/
NoSQL이란? | 비관계형 데이터베이스, 유연한 스키마 데이터 모델 | AWS
수십 년간, 애플리케이션 개발을 위해 가장 많이 사용된 데이터 모델은 Oracle, DB2, SQL Server, MySQL, PostgreSQL과 같은 관계형 데이터베이스에서 사용하는 관계형 데이터 모델이었습니다. 2000년대 중반
aws.amazon.com
https://www.mongodb.com/ko-kr/nosql-explained/nosql-vs-sql
NoSQL vs SQL Databases
Learn about the main differences between NoSQL and SQL Databases.
www.mongodb.com
https://lennilobel.wordpress.com/2015/06/01/relational-databases-vs-nosql-document-databases/
Relational Databases vs. NoSQL Document Databases
In this post, we’ll take a close look at some of the differences between a traditional relational store and a NoSQL document store. Rows vs. Documents To begin with, a document database stores enti…
lennilobel.wordpress.com
https://siyoon210.tistory.com/130
SQL vs NoSQL (MySQL vs. MongoDB)
※이 포스팅은 academind의 SQL vs. NoSQL을 번역한 포스팅입니다. [개요] 웹 애플리케이션 개발을 위한 첫 걸음을 내딛은 이후에 한가지 선택사항을 마주하게 됩니다. MySQL와 같은 SQL을 사용할 것인가?
siyoon210.tistory.com
http://happinessoncode.com/2017/07/29/cap-theorem-and-pacelc-theorem/
CAP 이론과 PACELC 이론을 알아보자
이번에 CAP 이론을 공부하면서 가장 많이 참고한 자료는 CAP Theorem: You don’t need CP, you don’t want AP, and you can’t have CA라는 싯다르타 레디(Siddhartha Reddy)의 영상이다. 영어라 듣기가 조금 어려웠지만
happinessoncode.com
https://phoenixnap.com/kb/acid-vs-base
ACID vs. BASE: Comparison of Database Transaction Models
ACID and BASE are two database transaction models, each with their own advantages and trade-offs. This article analyzes what they offer.
phoenixnap.com
https://stackoverflow.com/questions/4851242/what-does-soft-state-in-base-mean
What does 'soft-state' in BASE mean?
BASE stands for 'Basically Available, Soft state, Eventually consistent' So, I've come this far: "Basically Available: the system is available, but not necessarily all items in it at any given poi...
stackoverflow.com
[Redis] 이것이 레디스다(1) - NoSQL
사용자 증가로 인한 서비스 중단의 원인이 DB 서버일때, 너무 많은 SQL 문 처리 요청을 받아 MySQL이 동시에 처리할 수 있는 한계치를 넘어섰고 그로 인해 응답시간이 길어질 수 있다. MySQL 서버의
12bme.tistory.com
'CS > 데이터베이스' 카테고리의 다른 글
데이터베이스 Index란? (0) 2022.03.18 Redis란? (0) 2022.03.04 쿼리 프로세싱(Query processing) (0) 2021.12.14 트랜잭션 격리 수준(Isolation Level) (0) 2021.12.13 동시성 제어(Concurrency Control) (0) 2021.12.12
