-
kafka 조금 아는 척하기세미나, 영상 요약정리 2022. 6. 30. 00:01728x90
https://www.youtube.com/watch?v=0Ssx7jJJADI&list=PLwouWTPuIjUgr29uSrSkVo8PRmem6HRDE&index=4&t=4s
최범균님의 카프카 조금 아는척하기 영상 시리즈 1,2,3 + 공식문서의 내용을 요약한 내용입니다.
카프카란?
카프카 공식 페이지로 가면 카프카를 다음과 같이 소개하고 있습니다.
분산 이벤트 스트리밍 플랫폼
고성능
100개 중의 80개 이상의 회사가 사용한다이벤트 스트리밍이란?
어떤 하나의 사건을 이벤트라고 정의하며 이를 레코드 또는 메시지라고도 합니다.
카프카에서는 데이터를 읽거나 쓸 때 이벤트 단위로 작동합니다.
이벤트 스트리밍은 DB, 센서, 모바일 장치 등과 같은 이벤트 소스에서 이벤트 스트림 형태로
카프카의 구성요소
카프카는 크게 4가지 구성요소로 이루어집니다.
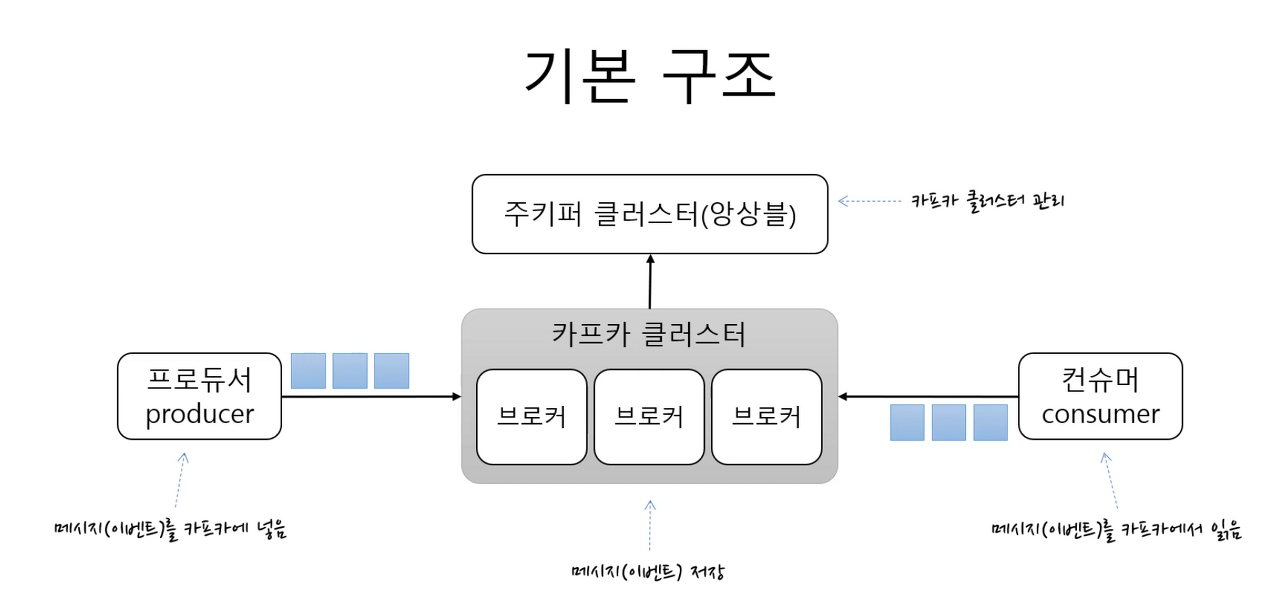
https://freedeveloper.tistory.com/396 1. 카프카 클러스터
메시지의 저장소로 여러개의 브로커로 구성됩니다.
브로커는 각각의 서버입니다.
2. 주키퍼 클러스터
카프카 클러스터를 관리합니다.
3. 프로듀서
메시지를 카프카에 넣습니다.
4. 컨슈머
메시지를 카프카에서 읽어옵니다.
토픽과 파티션
토픽
토픽은 메시지를 구분하는 단위입니다.
프로듀서는 어떤 토픽에 메시지를 저장하고 컨슈머는 어떤 토픽에서부터 메시지를 받아옵니다.
즉, 토픽을 기준으로 프로듀서와 컨슈머가 메시지를 주고받습니다.

또한 토픽은 위의 그림처럼 여러 파티션으로 구성될 수 있습니다.
topic1이 2개의 파티션으로 구성되어 있습니다. (p0, p1)
그러면 어떻게 topic1이 들어왔을 때 어떤 파티션에 저장해야 할까요?

프로듀서는 라운드로빈 또는 키로 파티션을 선택합니다.
그러면 여러개의 컨슈머는 topic을 어떻게 소비할까요?

한 개의 파티션은 컨슈머 그룹의 한 개 컨슈머만 연결할 수 있습니다.
즉, 컨슈머 그룹에 속한 컨슈머들은 한 파티션을 공유할 수 없습니다.
이로 인해 한 컨슈모그룹 기준으로 파티션의 메시지는 순서대로 처리가 보장됩니다.
파티션
추가만 가능한 파일입니다.
각 메시지 저장 위치를 offset이라고 합니다.
프로듀서가 넣은 메시지는 파티션의 맨 뒤에 추가됩니다.
컨슈머는 오프셋 기준으로 메시지를 순서대로 읽습니다.
우리가 흔히 아는 선입선출(큐) 구조로 이해하면 좋을 것 같습니다.

카프카가 고성능인 이유는?
- 파티션에 대한 파일IO를 메모리에서 처리합니다.
- 디스크버퍼에서 네트워크 버퍼로 직접 데이터 복사를 합니다 ( Zero Copy)
- 메세지 필터, 메시지 재전송과 같은 일은 브로커가 하지 않기 때문에 브로커가 하는 일이 비교적 단순합니다. (단순한 매핑관리)
- 묶어서 보내고 , 묶어서 받기( batch)
- 처리량 확장이 쉽다(1개 장비의 용량이 한계가 오면 브로커, 파티션을 추가하고 컨슈머가 느리면 컨슈머를 추가합니다) = 수평 확장이 쉽다
카프카의 리플리카
카프카는 장애가 났을 때를 대비하여 복제본을 가지고 있습니다.
복제수만큼 파티션의 복제본이 각 브로커에 생기며 이는 리더와 팔로워로 구성됩니다.
DB의 Master-Slave구조가 떠오릅니다.
프로듀서와 컨슈머는 리더를 통해서만 메시지를 처리할 수 있습니다.
팔로워는 리더로부터 복제됩니다.
만약 리더에 장애가 발생하면 다른 팔로워가 리더가 됩니다.

카프카 프로듀서 흐름도
다음코드는 프로듀서가 토픽에 메시지를 전송하는 코드입니다.
// Properties를 통해서 ack, batch사이즈 등의 설정 함 Properties prop = new Properties(); prop.put("bootstrap.servers", "kafka01:9092,kafka01:9092,kafka01:9092"); prop.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); prop.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // Properties를 이용해서 KafkaProducer 객체를 생성 함 KafkaProducer<Integer, String> producer = new KafkaProducer<>(prop); // KafkaProducer 객체는 send 메서드를 제공함 // send 메서드에 ProducerRecord를 전달을 함 // ProducerRecord가 Kafka Broker에 전송할 메시지가 됨 // ProducerRecord는 메시지를 크게 두가지 방법으로 생성할 수 있음 // 토픽이름과 key, value 를 사용해서 생성 producer.send(new ProducerRecord<>("topicname", "key", "value")); // 토픽이름과 value 를 사용해서 생성 producer.send(new ProducerRecord<>("topicname", "value")); // 사용 완료 후 close 메서드로 닫아줌 producer.close();프로듀서의 기본 흐름
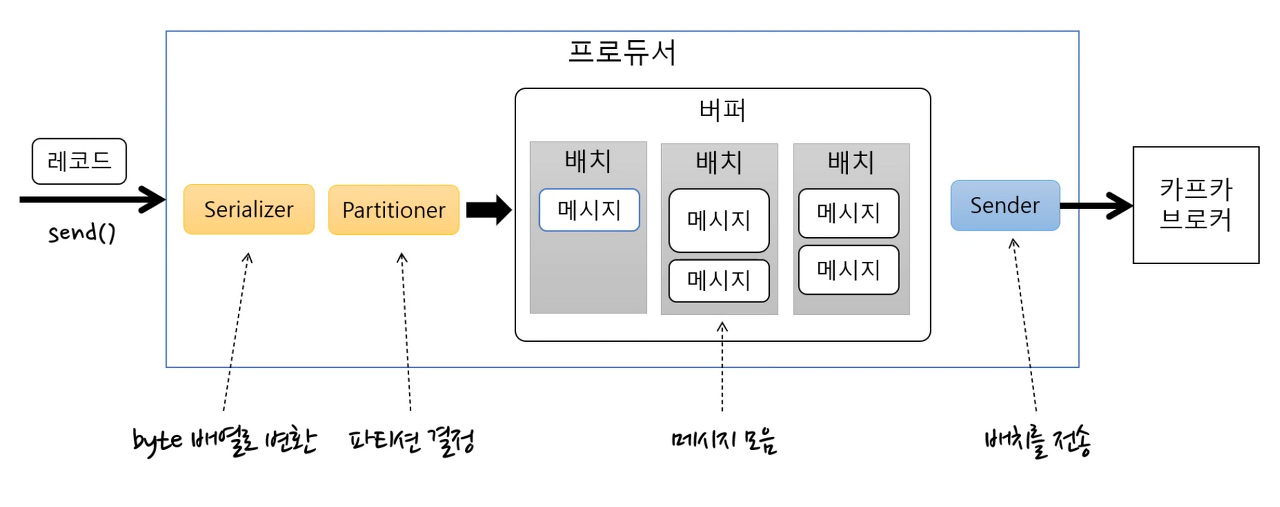
https://freedeveloper.tistory.com/397?category=909995 1.Serializer를 통해 byte 배열로 변환
2. Partitioner를 통해 메시지를 토픽의 어느 partition으로 보낼지 결정
3. 변환된 byte 배열 메시지를 배치로 묶어 버퍼에 저장
4. Sender가 배치를 가져와 카프카 브로커에게 전송
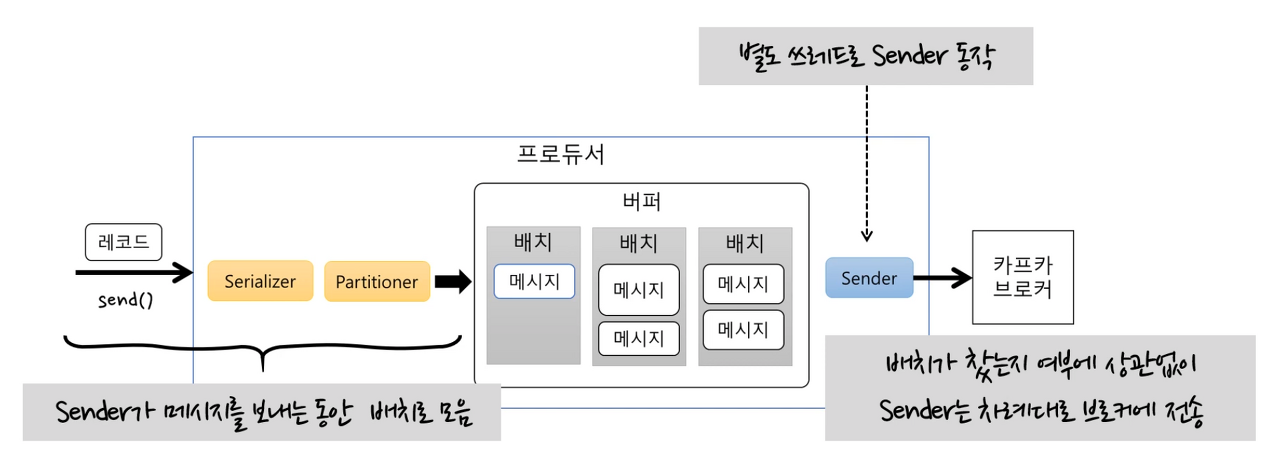
이때 send()메서드와 Sender는 별도쓰레드로 동작합니다.
send() 메서드는 계속하여 배치에 메시지를 누적시킵니다.
메시지가 배치가 찼는지 여부에 상관없이 브로커에 전송합니다.

위에서 별도 쓰레드로 동작하면서 메시지를 버퍼에 쌓고 가져다가 브로커에게 전송하는 모습을 봤습니다.
만약 배치 사이즈가 너무 작으면 전송 횟수가 많아지게되고 처리량이 떨어집니다.
즉, 배치를 가져오는 시간을 적절하게 설정해야지 한 번의 전송 요청에 더 많은 데이터 처리가 가능합니다.
프로듀서의 전송 결과
producer.send(new ProducerRecord<>("simple","value));아까 위에서 봤던 코드는 전송 실패를 알 수 없습니다.
만약 전송 결과를 확인하고 싶다면 다음과 같은 코드를 사용해야 합니다.
Future<RecordMetadata> f = producer.send(new ProducerRecord<>("topic","value")); try { RecordMetadata meta = f.get(); // 블로킹 } catch (ExecutionException ex) { }단, 블로킹이 발생하고 배치효과가 떨어져서 처리량이 저하됩니다.
처리량이 낮아도 되는 경우에만 사용합니다.
또한 Callback을 사용하는 방법이 존재합니다.
producer.send(new ProducerRecord<>("simple","value"), new Callback() { @Override public void onCompletion(RecordMetadata metadata, Exception ex) { } } });이 방식은 블로킹 방식이 아니라 처리량 저하가 없습니다.
프로듀서의 전송 보장
ACK를 사용하여 전송이 이루어졌는지 확인합니다.
마치 네트워크 TCP같네요
ack = 0
서버 응답을 기다리지 않습니다.
즉, 전송을 보장하지 않습니다
ack = 1
파티션의 리더에 저장되면 응답 받습니다.
하지만 리더 장애시에 메시지가 유실될 수 있습니다.
ack = all(또는 -1)
모든 리플리카에 저장되면 응답을 받습니다.
전송이 보장됩니다.
프로듀서의 에러 유형
전송 과정에서 실패
타임아웃
리더 다운에 의한 새 리더 선출 진행 중
브로커 설정 메시지 한도 초과
전송 전에 실패
직렬화 실패
프로듀서 버퍼가 차서 타임아웃
프로듀서 자체 요청 크기 제한 초과
실패 대응
재시도 가능한 에러는 재시도 처리(타임아웃, 일시적인 리더 없음 등)
아주 특별한 이유가 없다면 무한 재시도 X( 전체적인 메시지가 밀릴 수 있음)
추후 처리를 위해 기록(별도 파일, DB등에 실패 메시지를 기록하고 추후에 수동/자동으로 보정작업)
주의! 재전송시 메시지 중복가능 가능성도 존재합니다.

주의! 재시도시 메시지 저장순서가 변경될 수 있습니다.

컨슈머
다음은 특정 토픽 파티션에서 레코드 조회하는 코드입니다.
Properties prop = new Properties(); prop.put("bootstrap.servers","localhost:9092") prop.put("group.id","group1"); // group.id 지정 prop.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); prop.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // Properties를 이용해서 KafkaConsumer 객체를 생성 함 KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(prop); consumer.subscribe(Collections.singleton("simple")); // 토픽 구독 while(조건) { // 일정 시간 대기하면서 브로커로부터 컨슈머 레코드 목록을 읽어 온다 ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100)); // 읽어온 컨슈머 레코드 목록을 순회하며 필요한 처리를 진행 for (ConsumerRecord<String, String> records : records) { System.out.println(record.value() + ":" + record.topic() + ":" + record.partition() + ":" + record.offset()); } } // 사용 완료 후 close 메서드로 닫아줌 consumer.close();커밋과 오프셋

커밋과 오프셋 과정을 반복하여 메시지를 전송합니다.
자동커밋, 수동커밋 설정이 존재하며 자동커밋이 기본값입니다.
일정 주기로 컨슈머가 읽은 오프셋을 커밋하게 되며 기본값으로는 5초입니다.
또한 poll(), close() 메서드 호출 시 자동 커밋이 실행됩니다.
컨슈머 설정
fetch.min.bytes : 조회시 브로커가 전송할 최소 데이터 크기
fetch.max.wait.ms : 데이터가 최소 크기가 될 때까지 기다리는 시간
max.partition.fetch.bytes : 파티션 당 서버가 리턴할 수 있는 최대 크기
컨슈머의 재처리와 순서
일시적 커밋 실패, 리밴선드 등에 의해서 동일한 메시지를 조회할 수 있습니다.
따라서 컨슈머는 멱등성을 고려해야합니다.
만약 "조회수 1증가 -> 좋아요 1증가 조회수 1증가" 메시지를 처리한다고 가정하겠습니다.
위의 메시지를 재처리하면 조회수는 2가아닌 4가 될 수 있습니다.
즉, 데이터 특성에 따라 타임스탬프, 일련 번호 등을 활용해야 합니다.
세션 타임아웃과 하트비트
하트비트란 내가 살아있다는 것을 나타내거나, 다른 것이 살아있는지 점검 하는 메시지입니다.
컨슈머는 하트비트를 전송하여 연결을 유지합니다.
만약 브로커는 일정 시간 컨슈머로부터 하트비트가 오지 않으면 컨슈머를 그룹에서 제외하고 리밸런스가 진행됩니다.
컨슈머와 쓰레드
컨슈머는 멀티 쓰레드환경에서 안전하기 않기 때문에 주의해야 합니다.
출처
https://kafka.apache.org/intro
Apache Kafka
Apache Kafka: A Distributed Streaming Platform.
kafka.apache.org
https://www.youtube.com/watch?v=geMtm17ofPY
https://www.youtube.com/watch?v=xqrIDHbGjOY
'세미나, 영상 요약정리' 카테고리의 다른 글
왜 은행은 무한 스크롤이 안되나요 - 토스(이응준) (0) 2022.07.04 Java Native Memory Leak 원인을 찾아서 - 토스(박동호) (0) 2022.07.01 애자일이 도대체 뭐야? (0) 2022.06.28 [우아한테크토크] 선착순 이벤트 서버 생존기! (0) 2022.04.28 개발자가 질문 잘 하는 법 (0) 2022.04.28