-
[Java] Java Multi-Thread Programming의 모든것을 알아보자Java/자바를 더 깊게 2022. 3. 2. 01:53반응형
Multi-Thread란 무엇인가(What)?
우선 Multi-Thread에 대해 알아보기 전에 프로세스에 대해 먼저 알아보겠습니다.
프로세스란?
단순하게 말하자면 실행 중인 프로그램입니다.
프로그램을 실행하면 OS로부터 실행에 필요한 자원(메모리)을 할당받아 프로세스가 됩니다.

프로그램 우리가 친숙한 바탕화면의 실행 아이콘들이 프로그램입니다.
프로세스 프로세스는 CPU, 메모리, 디스크, 네트워크 등의 자원을 사용하고 있습니다.
이클립스가 메모리를 1GB사용하고있네요.
프로세스는 프로그램을 수행하는데 필요한 데이터와 메모리 등의 자원 그리고 스레드로 구성되어 있습니다.
프로세스의 자원을 이용해서 실제로 작업을 수행하는 것이 바로 스레드입니다.
따라서 모든 프로세스에는 최소한 하나 이상의 스레드가 존재하며, 둘 이상의 스레드를 가진 프로세스를 Multi-Thread 프로세스라고 합니다.
단일 스레드 vs 멀티 스레드를 보여주는 가장 직관적이고 유명한 그림을 가져왔습니다.
https://www.youtube.com/watch?v=kNNHaAaFDs8 멀티 스레드의 장점(Why?)
1. 자원을 보다 효율적으로 사용할 수 있다.
2. 사용자에 대한 응답성이 향상된다.
3. 작업이 분리되어 코드가 간결해집니다.
메신저로 채팅하면서 파일을 다운로드하거나 음성 대화를 나눌 수 있는 것이 가능한 이유가 바로 멀티스레드가 동작하기 때문입니다.
만약 싱글 스레드로 동작한다면 파일을 다운로드하는 동안에는 다른 일을 전혀 할 수 없습니다.
여러 사용자에게 서비스를 해주는 서버 프로그램일 경우 멀티스레드가 필수적이며 하나의 서버 프로세스가 여러 개의 스레드를 생성해서 사용자의 요청이 1:1로 처리되도록 해야 합니다.
그러면 무조건 스레드의 개수를 많이 하면 좋은 것 아닌가요?
스레드의 개수는 제한되어 있지 않지만 쓰레드가 작업을 수행하는데 개별적인 메모리 공간(호출스택)이 필요하기 때문에 프로세스의 메모리 한계에 따라 생성할 수 있는 쓰레드의 수가 결정됩니다.
또한 CPU의 코어가 한 번에 단 하나의 작업만 수행할 수 있으므로 실제로 동시에 처리되는 작업의 개수는 코어의 개수와 일치합니다.
쓰레드의 수는 언제나 코어의 개수보다 훨씬 많기 때문에 각 코어가 아주 짧은 시간 동안 여러 작업을 번갈아 가며 수행함으로써 여러 작업들이 모두 동시에 수행되는 것처럼 보이게 합니다.
따라서 프로세스의 성능이 단순히 쓰레드의 개수에 비례하는 것은 아니며, 하나의 스레드를 가진 프로세스보다 두 개의 스레드를 가진 프로세스가 오히려 더 낮은 성능을 보일 수도 있습니다.
동시성과 병렬성의 차이
하나의 코어에서 여러 스레드가 실행되는 것을 동시성(Context switching이 발생하고 내부적으로 계속 번갈아가면서 진행) - 빠르게 번갈아가면서 수행하기 때문에 동시에 수행되는 것처럼 보이나 그렇지 않음
멀티 코어에서 코어별로 개별 쓰레드가 실행되는 것을 병렬성이라 합니다.

https://www.notion.so/ac23f351403741959ec248b00ea6870e 싱글코어의 싱글 스레드와 멀티스레드의 수행의 수행방법 (사진 출처)

싱글 쓰레드 
멀티 쓰레드 싱글 코어 이므로 A와 B의 작업이 겹치며 수행되지 않습니다.
만약 멀티 코어라면 A와 B의 작업이 겹칠 수 있으며 하나의 자원을 놓고 두 스레드가 경쟁할 수 있습니다.
싱글 스레드와 멀티쓰레드의 수행 속도 비교
싱글쓰레드
public class ThreadTest { public static void main(String[] args) { long startTime = System.currentTimeMillis(); for(int i=0; i<300;i++) { System.out.printf("%s", new String("-")); } System.out.println("소요시간1:" + (System.currentTimeMillis() - startTime)); for(int i=0; i<300;i++) { System.out.printf("%s", new String("|")); } System.out.println("소요시간2:" + (System.currentTimeMillis() - startTime)); } }하나의 스레드가 '-'와 'l'를 출력하는 예제입니다.
소요시간 1 : 26
소요시간 2 : 31
멀티스레드
public class ThreadTest { static long startTime = 0; public static void main(String[] args) { MyThread1 th1 = new MyThread1(); th1.start(); startTime = System.currentTimeMillis(); for (int i = 0; i < 300; i++) { System.out.printf("%s", new String("|")); } System.out.println("소요시간:" + (System.currentTimeMillis() - startTime)); } } class MyThread1 extends Thread { @Override public void run() { for (int i = 0; i < 300; i++) { System.out.printf("%s", new String("-")); } System.out.println(System.currentTimeMillis() - ThreadTest.startTime); } }2개의 스레드가 '-'와 'l'를 출력하는 예제입니다.
소요시간 1 : 32
소요시간 2 : 34
오히려 단일 스레드보다 멀티스레드가 시간이 더 많이 소요됩니다.
두 스레드가 번갈아 가면서 작업을 처리하기 때문에 쓰레드간의 작업전환시간이 소요되며, 한 쓰레드가 화면에 출력하고 있는 동안 다른 쓰레드는 출력이 끝나기를 기다려야하는 대기시간이 존재하기 때문입니다.
하지만 두 쓰레드가 서로 다른 자원을 사용하는 작업의 경우에는 싱글 스레드 프로세스보다 멀티스레드 프로세스가 더 효율적입니다.
예를 들어, 사용자로부터 데이터를 입력받는 작업, 네트워크로 파일을 주고받는 작업, 프린터로 파일을 출력하는 작업 등 외부기기와 입출력이 필요한 경우가 이에 해당됩니다.
멀티 스레드의 단점
1. 동기화(Synchronization)
2. 교착상태(DeadLock)
단점에 대해서는 밑에서 더 자세하게 다루어 보겠습니다.
쓰레드의 구현과 실행(How?)
스레드를 사용하기 위한 2가지 방법이 존재합니다.
1. Thread 클래스를 상속 - run() 메서드를 오버 라이딩
class MyThread1 extends Thread { @Override public void run() { for (int i = 0; i < 300; i++) { System.out.printf("%s", new String("-")); } System.out.println(System.currentTimeMillis() - ThreadTest.startTime); } } MyThread1 t1 = new MyThread1(); t1.start();2. Runnable 인터페이스를 구현 - run () 메서드를 구현
class MyThread2 implements Runnable{ @Override public void run() { // TODO Auto-generated method stub for(int i=0; i<300; i++) { System.out.println("|"); } } } Runnable r = new MyThread2(); Thread t2 = new Thread(r); t2.start();두 방법 모두 스레드를 생성한 후 start() 메서드를 호출해야 스레드가 작업을 시작합니다.
start 하게 되면 시작 가능한 상태가 되는 것이지 바로 시작하는 건 아닙니다.
스레드의 순서는 OS 스케쥴러가 실행 순서를 결정하게 됩니다.(Java는 OS에 독립적이라고 하지만 스레드는 OS에 의존적)
따라서 아래의 코드는 t1 스레드가 먼저 실행된다고 보장할 순 없습니다.
t1.start(); t2.start();우리는 run() 메서드를 overried 해서 사용하는데 thread.start() 메서드를 호출하는 이유는 무엇일까요?

https://velog.io/@pond1029/JVM JVM의 Runtime data area는 위의 그림처럼 이루어져 있습니다.
Thread1이 보이고 그 뒤에 여러 스레드들이 존재할 수 있음을 암시하고 있습니다.
위의 그림을 통해 스레드 별로 호출 스택이 있는 것도 알 수 있습니다.

https://www.youtube.com/watch?v=P1zDndoy4pI&amp;amp;amp;amp;amp;t=31s main 함수가 start 메서드를 호출 스택에 쌓습니다.

https://www.youtube.com/watch?v=P1zDndoy4pI&amp;amp;amp;amp;amp;t=31s start 메서드가 새로운 호출 스택을 생성합니다.
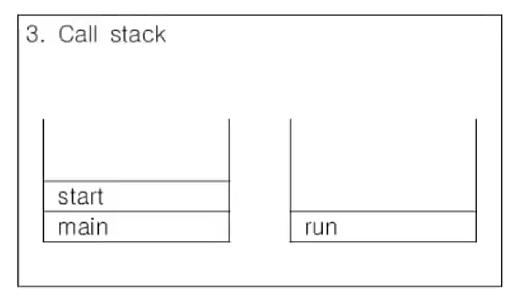
https://www.youtube.com/watch?v=P1zDndoy4pI&amp;amp;amp;amp;amp;t=31s start 메서드가 run메서드를 새로운 호출 스택에 push 하고 종료됩니다.

https://www.youtube.com/watch?v=P1zDndoy4pI&amp;amp;amp;amp;amp;t=31s 각각의 스레드가 다른 호출 스택을 가짐으로써 서로 독립적인 작업을 할 수 있습니다.
만약 t1.run이 호출된다면 단지 main 스레드에 run() 메서드가 push 될 것입니다.
그러면 Thread 클래스 / Runnable 인터페이스 둘 중 어떤 것을 사용해야 할까요?
클래스와 인터페이스의 차이에 대해 이해하신다면 상황에 따라 사용하실 수 있습니다.
자바의 클래스는 단일 상속만 지원하고 인터페이스는 다중 상속을 지원합니다.
따라서 Thread 클래스를 상속받으면 다른 클래스는 상속받지 못합니다.
스레드의 우선순위
스레드는 우선순위라는 멤버 변수를 가지고 있어, 이 값에 따라 스레드가 얻는 실행시간이 달라집니다.
우선순위에 따라 특정 쓰레드가 더 많은 작업시간을 갖게 할 수 있습니다.
public final static int MIN_PRIORITY = 1; public final static int NORM_PRIORITY = 5; public final static int MAX_PRIORITY = 10;main thread의 우선순위는 5이며 우선순위의 범위는 1~10까지로 숫자가 높을수록 우선순위가 높습니다.
하지만 이는 절대적이지 않고 OS마다 다른 방식으로 스케쥴링을 하기 때문에 어떤 OS에서 실행하느냐에 따라 다른 결과를 얻을 수 있습니다. 굳이 우선순위에 차등을 두어 스레드를 실행시키고 싶다면 특정 OS의 스케쥴링 정책과 JVM의 구현을 직접 확인해보아야 합니다.
쓰레드 그룹
서로 관련된 쓰레드를 그룹으로 묶어서 다루기 위한 것
모든 스레드는 반드시 하나의 쓰레드 그룹에 포함되어 있어야 합니다.
쓰레드 그룹을 지정하지 않고 생성한 쓰레드는 'main 쓰레드 그룹'에 속합니다.
기본적으로 우리가 생성한 스레드도 main 쓰레드에서 생성하기 때문에 main 쓰레드 그룹에 속하며 main 쓰레드의 우선순위(5)를 상속받습니다.
왜 쓰레드 그룹을 묶어서 관리할까요?
만약 특정 스레드들을 삭제하거나 interrupt 하고 싶은데 그룹이 존재하지 않는다면 모든 스레드에 일일이 해당 메서드를 호출해야 합니다.
그룹을 묶어서 관리한다면 일괄적으로 메서드를 호출하여 편리하게 관리할 수 있습니다.
사용자 스레드와 데몬 쓰레드
사용자 쓰레드
실행 중인 사용자 스레드가 하나도 없을 때 프로그램은 종료됩니다.
main 쓰레드가 사용자 스레드에 해당됩니다.
우리가 생성한 스레드들도 사용자 스레드에 해당합니다.
따라서 main 스레드가 종료되더라도 우리가 생성한 쓰레드가 수행 중이라면 프로그램은 나머지 사용자 스레드들이 종료될 때까지 실행됩니다.
데몬 쓰레드
사용자 스레드의 작업을 돕는 보조적인 역할을 수행합니다.
사용자 스레드가 모두 종료되면 자동적으로 종료됩니다.
GC, 자동 저장, 화면 자동갱신 등에 사용됩니다.
무한루프와 조건문을 이용해서 실행 후 대기하다가 특정 조건이 만족되면 작업을 수행하고 다시 대기하도록 작성합니다.
사용자 스레드가 종료되면 자동적으로 종료되므로 무한루프를 수행해도 관계없습니다.
계속 수행되면 핵심 로직을 수행할 수 못할 수 있으므로 중간에 sleep() 메서드를 활용하여 쉬는 시간을 줍니다.
setDeamon(true/ false) 메서드를 통해 스레드를 사용자 쓰레드 또는 데몬 스레드로 변경할 수 있습니다.
단! start() 메서드를 호출하기 전에 실행되어야 합니다.
스레드의 상태
스레드가 혼자라면 계속 실행하겠지만 여러 개의 쓰레드가 존재하게 된다면 작업을 하기 위해 기다리는 상황이 필연적으로 연출이 됩니다.
따라서 스레드에는 다섯 가지 상태가 존재합니다.

쓰레드의 상태도(http://egloos.zum.com/stilyou13/v/1025725) NEW
스레드가 생성되고 아직 start()가 호출되지 않은 상태
RUNNABLE or RUNNING
실행 중 또는 실행 가능한 상태
start(), resume(), notify(), interrupt(), time-out 상황
WAITING, TIMED_WAITING, BLOCKED
스레드의 작업이 종료되지는 않지만 실행 가능하지 않은 상태, 일시정지 상태
동기화 블록에 의해서 일시 정지된 상태(lock이 풀릴 때까지 기다리는 상태)
sleep(), join(), wait(), suspend(), I/O block 상황
TERMINATED
쓰레드의 작업이 종료된 상태
스레드가 종료되거나 stop() 메서드가 호출된 상황
스레드의 실행 제어
sleep()
지정된 시간 동안 스레드를 일시정지(WAITING)시킵니다.
지정한 시간이 지나게 나면, 자동적으로 다시 실행 대기상태(RUNNABLE)가 됩니다.
InterruptedException 예외처리를 반드시 해야 합니다.
진짜 에러를 처리하기 위해 예외처리는 하는 것이 아니라 스레드를 중간에 깨우기 위해 try-catch를 사용합니다.
만약 delay() 메서드를 따로 만들어서 사용한다면 코드를 좀 더 깔끔하게 사용할 수 있습니다.
void delay(log millis){ try{ Thread.sleep(millis); } catch(InterruptedException e){} }또한 static 메서드이기 때문에 특정 쓰레드를 지정해서 멈추게 하는 것은 불가능합니다.
따라서 MyThread1 th1 = new MyThread1();으로 스레드를 선언한 경우에
th1.sleep()을 하는 것보다는 MyThread1.sleep()이 권장됩니다.

다음 코드는 어떻게 실행될까요?
public class ThreadSleepTest { public static void main(String[] args) { // TODO Auto-generated method stub MyThread1 th1 = new MyThread1(); MyThread2 th2 = new MyThread2(); th1.start(); th2.start(); try { th1.sleep(2000); } catch (InterruptedException e) {} System.out.println("<<main 종료>>"); } } class MyThread1 extends Thread{ public void run() { for(int i=0; i< 300; i++) System.out.print("-"); System.out.println("<<th1 종료>>"); } } class MyThread2 extends Thread{ public void run() { for(int i=0; i< 300; i++) System.out.print("|"); System.out.println("<<th2 종료>>"); } }th1 스레드만 sleep 되고 th2 스레드는 시작되고 있을까요?
main Thread가 th1, th2 Thread를 생성하기 때문에 main Thread가 2초 동안 일시 정지되며 "<<main 종료>>"가 2초 뒤에 출력됩니다.
즉, Thread.sleep()와 같은 기능으로 동작합니다.
그러면 th1.sleep() 대신에 MyThread1.sleep()을 하면 th1 만 일시 정지되고 th2는 시작되고 있을까요?
마찬가지로 main Thread가 th1, th2 Thread를 생성하기 때문에 main Thread가 2초 동안 일시 정지되며 "<<main 종료>>"가 2초 뒤에 출력됩니다.
이 또한 Thread.sleep()과 동일하며 특정 Thread를 지정해서 멈출 수 없습니다.
그러면 th1 스레드를 일시 정지시키고 싶은데 불가능할까요?
class MyThread1 extends Thread{ public void run() { try { this.sleep(2000); } catch (InterruptedException e) {} for(int i=0; i< 300; i++) System.out.print("-"); System.out.println("<<th1 종료>>"); } }이렇게 해당 쓰레드 클래스 안에서 sleep()을 주게 된다면 th1 스레드만 일시 정지시킬 수 있습니다.
interrupt()
sleep()이나 join()에 의해 일시 정지상태인 스레드를 깨워서 실행 대기상태로 만듭니다.
또는 쓰레드를 작업을 취소하기 위해 사용합니다.
만약 큰 파일을 다운로드할 때 시간이 너무 오래 걸리면 중간에 다운로드를 포기하고 취소할 수 있어야 합니다.
스레드가 실행 중에 있을 때 interrupt()를 사용하여 스레드에게 작업을 멈추라고 요청할 수 있습니다.
하지만 단지 멈추라고 요청하는 것일 뿐 스레드를 강제로 종료시키지는 못합니다.
즉, interrupt()는 그저 스레드의 interruped상태(인스턴스 변수)를 바꾸기만 합니다.
sleep() 메서드와 동일하게 static 메서드가 존재합니다.
void interrupt() //쓰레드의 interrupted상태를 false에서 true로 변경. boolean isInterrupted() //쓰레드의 interrupted상태를 반환. static boolean interrupted() //현재 쓰레드의 interrupted상태를 반환 후, false로 변경stop(), resume(), suspend()
스레드를 종료(stop) / 재개(resume) / 일시정지(suspend) 시키는 메서드들입니다.
@Deprecated 어노테이션이 붙어있습니다.
해당 어노테이션은 더 이상 사용하지 않음을 권장합니다.
suspend()는 대상 스레드가 lock이 된 상태에서 일시 정지된 경우가 존재할 수 있습니다.
즉, Dead-lock(교착 상태)가 발생하기 쉽습니다.
stop()은 모든 모니터의 잠금을 해제하도록 합니다. 모니터에 의해 보호된 객체가 일관성 없는 상태에 있었다면 다른 스레드는 이 객체를 일관성 없는 상태로 접근할 수 있습니다. 이 과정 속에서 프로그램이 손상될 수 있습니다.
모니터란?
monitor는 여러 스레드가 객체로 동시에 객체로 접근하는 것을 막는다.
그러면 어떤 방법을 사용해서 스레드를 멈추나요?
private volatile Thread blinker; public void stop() { blinker = null; } public void run() { Thread thisThread = Thread.currentThread(); while (blinker == thisThread) { try { Thread.sleep(interval); } catch (InterruptedException e){ } repaint(); } }while문에 조건을 달아주는 방식을 사용하거나 / 아니면 interrupt() 메서드를 사용해서 쓰레드를 멈출 수 있습니다.
join()
지정된 시간 동안 특정 스레드가 작업하는 것을 기다립니다.
지정된 시간이 지나거나 특정 스레드의 작업이 종료되면 join()을 호출한 스레드로 다시 돌아와 실행을 계속합니다.
void join() //작업이 모두 끝날때 까지 void join(long millis) //천분의 일초 동안 기다림 void join(long millis, int nanos) //천분의 일초 + 나노초 동안 기다림public class ThreadJoinTest { public static void main(String[] args) { // TODO Auto-generated method stub MyJoinThread1 th1 = new MyJoinThread1(); MyJoinThread2 th2 = new MyJoinThread2(); th1.start(); th2.start(); try { th1.join(); } catch(InterruptedException e) {} //delay(2000); System.out.println("<<main 종료>>"); } static void delay(long millis) { try { MyThread1.sleep(millis); } catch (InterruptedException e) {} } } class MyJoinThread1 extends Thread{ public void run() { for(int i=0; i< 300; i++) System.out.print("-"); System.out.println("<<th1 종료>>"); } } class MyJoinThread2 extends Thread{ public void run() { for(int i=0; i< 300; i++) System.out.print("|"); System.out.println("<<th2 종료>>"); } }main 스레드에서 th1.join()을 호출하기 때문에 th1 스레드가 끝날 때까지 main 스레드는 종료되지 않습니다.
하지만 th1.join()을 호출하지 않는다면 바로 "<<main 종료>>" 구문이 출력될 것입니다.
yield()
실행 중에 자신에게 주어진 실행시간을 다른 스레드에게 양보하고 자신은 실행 대기상태가 됩니다.
만약 스케쥴러에 의해 1초의 실행시간을 할당받은 스레드가 0.5초 동안 작업한 상태에서 yield()가 호출되면, 나머지 0.5초는 포기하고 다시 실행 대기상태가 됩니다.
yield()와 interrupt()를 적절히 사용하면, 응답성과 효율을 높일 수 있습니다.
예를 들어 스레드가 일시정지상태라면 yield()를 호출합니다.
스레드의 동기화(synchronization)
멀티 쓰레드 프로세스에서는 어떤 스레드가 하는 작업이 다른 스레드의 작업에 영향을 미칠 수 있습니다.
따라서 진행 중인 작업이 다른 스레드에게 간섭받지 않게 하려면 '동기화'가 필요합니다.
다음 코드는 어떻게 동작할까요?
public class ConcurrentTest { private static int count = 0; public void IncreaseCount(){ count++; } public static void main(String[] args) { Runnable r = new ConcurrentThread(); Thread th1 = new Thread(r); Thread th2 = new Thread(r); th1.start(); th2.start(); try { th1.join(); th2.join(); } catch (InterruptedException e) {} System.out.println(count); } } class ConcurrentThread implements Runnable{ ConcurrentTest ct = new ConcurrentTest(); @Override public void run() { for(int i=0; i<10_000; i++) { ct.IncreaseCount(); } } }ConcurrentThread는 10000번 반복하며 static 변수인 count를 증가시킵니다.
이러한 스레드가 2개가 실행됩니다.
이후에 스레드가 끝나기 전에 main 쓰레드가 count를 출력하면 안되므로 join()을 통해 모든 쓰레드가 다 종료되면 count를 출력하도록 합니다.
count는 20,000이 나오게 될까요?
실행할 때마다 값이 다르게 나오지만 17000~ 18000 정도의 값이 출력됩니다.
멀티 스레드 프로세스에서 다른 스레드의 작업에 영향을 미치는 것입니다.
count의 값이 2인데 만약 두 스레드에서 동시에 count값을 가져온 뒤 count++을 합니다.
원래라면 4가 되어야 하지만 2의 값을 가져왔기 때문에 3이 반환됩니다.
이런 경우가 누적되어 20,000보다 낮은 수가 나오게 됩니다.
따라서 동기화가 필요합니다.
간섭받지 않아야 하는 문장들을 '임계 영역'으로 설정하여 락(lock)을 얻은 단 하나의 스레드만 사용할 수 있습니다.
하지만 임계 영역이 길면 길수록 성능이 감소할 것이며 임계 영역이 짧으면 짧을수록 성능이 증가합니다.
하지만 임계 영역이 짧으면 위와 같이 동시성 문제가 발생할 수 있으니 적절한 임계 영역을 설정하는 것이 중요합니다.
synchronized를 이용한 동기화
1. 메서드 전체를 임계 영역으로 지정 public synchronized void IncreaseCount(){ count++; } 2. 특정한 영역을 임계 영역으로 지정 public void IncreaseCount(){ synchronized(this) { count++; } }위의 코드를 synchronized를 통해 1번 또는 2번으로 수정한다면 20000이 정상적으로 출력됩니다.
wait()와 notify()
동시성 문제를 대비하기 위해 특정 스레드가 객체의 락을 가짐으로써 공유 데이터를 보호하는 것 까지는 좋습니다.
하지만 특정 쓰레드가 락을 가진 상태로 오랜 시간을 보내지 않도록 하는 것도 중요합니다.
만약 계좌에 출금할 돈이 부족해서 한 쓰레드가 락을 보유한 채로 돈이 입금될 때까지 오랜 시간을 보낸다면, 다른 스레드들은 모두 해당 객체의 락을 기다리느라 다른 작업들도 원활히 진행되지 않습니다.
이를 해결하기 위해 wait()와 notify()가 고안되었습니다.
만약 실행 중인 쓰레드에 wait()이 호출되면, 실행 중인 스레드는 해당 객체의 waiting pool에서 대기합니다.
만약 notify()가 호출되면, 해당 객체의 waiting pool에 있던 모든 스레드들 중에서 임의의 스레드만 통지를 받습니다.
notifyAll()을 사용하면 모든 스레드들에게 통보 하지만 lock을 얻을 수 있는 것은 하나의 스레드일 뿐이므로 lock을 얻지 못한 스레드들은 모두 다시 lock을 기다리게 됩니다.
void wait() void wait(long timeout) void wait(long timeout, int nanos) void notify() void notifyAll()synchronized 블록 내에서만 사용 가능하며 Object 클래스에 정의되어 있습니다.
보다 효율적인 동기화를 위해 사용됩니다.
wait()은 notify() 또는 notifyAll()이 호출될 때까지 기다리지만 매개변수가 있는 wait(long timeout), wiat(long timeout, int nanos)의 경우에는 지정된 시간 동안만 기다립니다.
java.util.concurrent.locks 패키지의 Lock클래스를 이용한 동기화
//방법1 메서드안에 lock 걸기 Lock lock = new ReentrantLock(); public void IncreaseCount(){ lock.lock(); count++; lock.unlock(); } //방법2 메서드 외부에 lock 걸기 class ConcurrentThread implements Runnable{ ConcurrentTest ct = new ConcurrentTest(); Lock lock = new ReentrantLock(); @Override public void run() { for(int i=0; i<10_000; i++) { lock.lock(); ct.IncreaseCount(); lock.unlock(); } } }JDK 1.5에 추가된 lock클래스를 이용하는 방법입니다.
지금은 lock(), unlock()을 바로 호출하였지만 만약 ct.IncreaseCount()가 Exception을 발생시킨다면 lock()을 그대로 소유하고 있기 때문에 try-catch-finally를 사용하여 finally 구문에 항상 unlock()을 사용하는 게 바람직합니다.
synchronized vs Lock
모든 스레드가 자신의 작업을 수행할 기회를 공평하게 갖는 것에 대한 공정성의 차이가 존재합니다.
Lock의 경우에는 생서자의 인자를 통해 공저/불공정 설정을 할 수 있는 반면에 synchronized는 공정성을 지원하지 않습니다.
즉, 공정성이 존재할 경우에는 경쟁( 쓰레들끼리 서로 자원을 할당받기 위해 대기)이 발생했을 때 가장 오랫동안 기다린 스레드에게 기회를 제공합니다.
하지만 Synchronized는 최악의 경우 자원을 계속 할당받지 못하는 starvation(기아 상태)가 될 수도 있습니다.
Lock 클래스의 종류
ReetrantLock //가장 일반적인 배타적인 락 ReetrantReadWriteLock //읽기에는 공유적이고, 쓰기에는 배타적인 lock StampedLock //ReetrantReadWriteLock에 낙관적인 lock의 기능을 추가공유적과 배타적이라는 말이 이해가 안 될 수도 있습니다.
공유적이란 말은 어떤 스레드가 읽기 lock을 걸었다면 다른 쓰레드도 읽기 lock을 수행할 수 있습니다.
읽기는 내용을 변경하지 않으므로 동시에 여러 쓰레드가 읽어도 문제가 되지 않기 때문입니다.
하지만 쓰기의 경우에는 허용되지 않습니다.
하지만 동시에 쓰기/쓰기가 일어나거나 쓰기/읽기, 읽기/쓰기 즉 쓰기가 한 번이라도 포함되면 문제가 발생할 수 있습니다.
따라서 쓰기에는 배타적인 lock을 사용하여 동시에 여러 스레드가 관여할 수 없도록 합니다.
이것에 바로 ReetrantLock과 ReetrantReadWriteLock의 차이점입니다.
StreamedLock은 lock을 걸거나 해제할 때 '스탬프(long type의 정수 값)'를 사용하며 읽기 쓰기를 위한 lock 이외에 낙관적 읽기 lock이 추가되어 있습니다.
읽기 lock이 걸려있으면 , 쓰기 lock을 얻기 위해서는 읽기 lock이 풀릴 때까지 기다려야 합니다.
하지만 낙관적 읽기 lock은 쓰기 lock에 의해 바로 풀려버립니다.
따라서 낙관적 읽기에 실패하면 읽기 lock을 다시 얻어와 읽어야 합니다.
ReentrantLock과 Condition
wait()와 notify()를 사용하게 되었을 때 특정 스레드들을 구분하여 통제하지 못하는 단점이 존재합니다.
Condition을 사용한다면 이 문제점을 해결할 수 있습니다.
공유 객체의 waiting pool에 넣는 대신에 각각의 스레드를 위한 Condition을 만들어서 쓰레드를 기다리도록 합니다.
Condition은 이미 생성된 lock으로부터 newCondition() 메서드를 호출하여 생성할 수 있습니다.
private ReentrantLock lock = new ReentrantLock(); private Condition forCook = lock.newCondition(); private Condition forCust = lock.newCondition();wait() 대신에 await()를 사용합니다.
notify() 대신에 signal()을 사용합니다.
이제 forCook.await()를 하면 요리사를 기다리게 할 수 있으며 forCust.await()를 하면 고객을 기다리게 할 수 있습니다.
이처럼 Condition을 사용한다면 대기와 통지의 대상을 명확하게 구분할 수 있습니다.
Volatile
volatile keyword는 Java 변수를 Main Memory에 저장하겠다는 것을 명시합니다.
매번 변수의 값을 Read 할 때마다 CPU cache에 저장된 값이 아닌 Main Memory에서 읽는 것입니다.
또한 변수의 값을 Write 할 때마다 Main Memory에 까지 작성하는 것입니다.
그러면 Volatile을 왜 사용할까요?

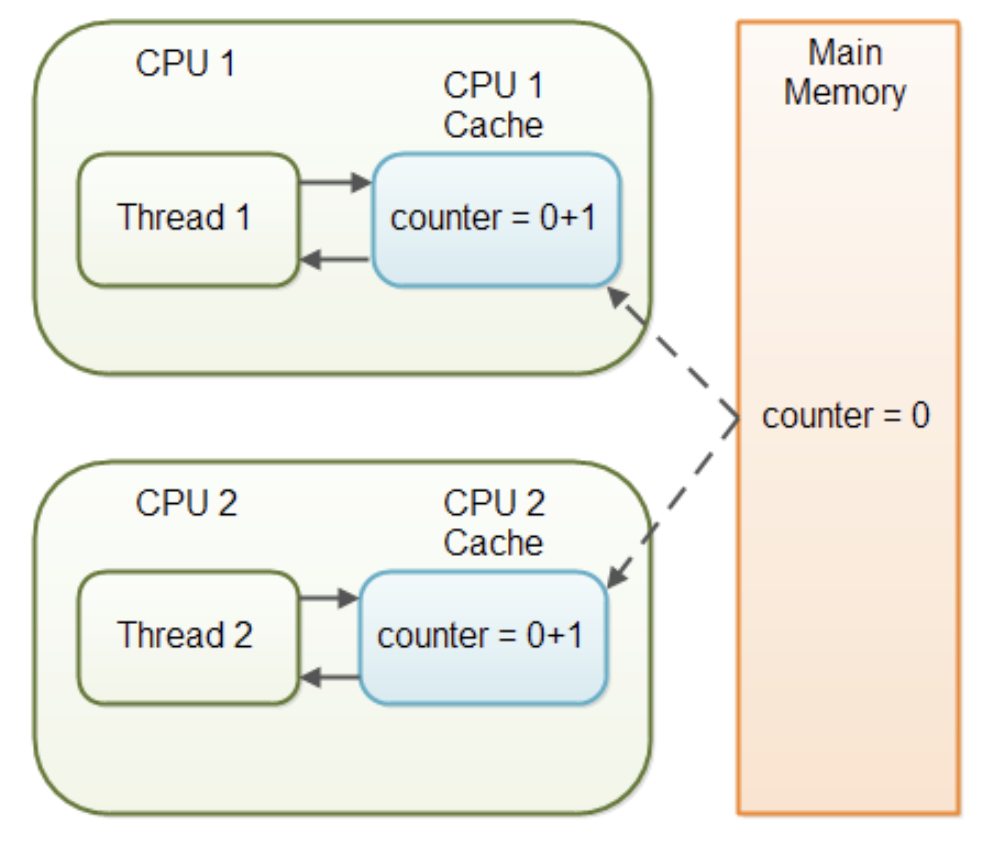
http://tutorials.jenkov.com/java-concurrency/volatile.html volatile 변수를 사용하고 있지 않는 Multi Core애플리케이션에서는 Task를 수행하는 동안 성능 향상을 위해 Main Memory에서 읽은 변수 값을 CPU Cache에 저장하게 됩니다.
만약에 Multi Core 환경에서 Thread가 변수 값을 읽어올 때 각각의 CPU Cache에 저장된 값이 다르기 때문에 변수 값이 일치하지 않는 문제가 발생하게 됩니다.
만약 어떤 Object를 공유하는 2개의 스레드가 있습니다.
public class SharedObject{ public int counter = 0; }Thread1은 counter 값을 더하고 읽는 연산을 수행합니다.
Thread 2는 counter 값을 읽기만 합니다.
Thread1은 counter값을 증가시키고 있지만 CPU Cache에만 반영되어 있고 실제로 Main Memory에는 반영이 되지 않습니다.
그렇기 때문에 Thread2는 count값을 계속 읽어도 오지만 0을 가져오는 문제가 발생합니다.

http://tutorials.jenkov.com/java-concurrency/volatile.html public class SharedObject{ public volatile int counter = 0; }volatile 키워드를 활용하면 Main Memory에 저장되고 읽어오기 때문에 위의 문제를 해결할 수 있습니다.
하지만 volatile 키워드를 사용해도 동시성 문제까지는 해결할 수 없습니다.
http://tutorials.jenkov.com/java-concurrency/volatile.html Thread1은 counter 값을 더하고 읽는 연산을 수행합니다.
Thread 2는 counter 값을 더하고 읽는 연산을 수행합니다.
두 스레드가 모두 읽고 쓰는 연산을 했을 때 동시에 메모리에서 0의 값을 가져와서 쓸 수 있습니다.
이 경우에는 원래라면 counter = 2 가 되어야 하지만 1 값이 써지게 됩니다.
따라서 Synchonized / Lock 등의 활용하여 동시성 문제를 해결해야 합니다.
Atomic 클래스
java.util.concurrent 패키지안에 속해있는 클래스로써 단일 변수에 대해 thread-safe 프로그래밍을 지원합니다.
CAS(Compare and Swap) 방식을 사용하는데 이는 간단하게 비교하고 바꿉니다.
즉, 변수의 값을 변경하기 전에 기존의 값이 내가 예상하던 값과 같을 때만 새로운 값으로 할당합니다.
만약 2라는 값을 가져와서 +1하고 저장하려고 했을 때 기존의 값이 2라면 새로운 값인 3을 할당하고 기존의 값이 2가 아닌 3이라면 이 값을 할당하지 않습니다.
Atomic vs Volatile
volatile 키워드는 오직 한 개의 쓰레드에서 쓰기 작업 / 다른 쓰레드는 읽기작업을 할 때만 사용
AtomicBoolean, AtomicInteger는 여러 쓰레드에서 읽기/쓰기 작업을 병행할 수 있습니다.
스핀 락, 뮤텍스, 세마포어 알아보기
스핀 락(Spin Lock)
임계 구역에 진입이 불가능할 때(=내가 사용하고 싶은 자원을 다른 곳에서 사용하고 있을 때) 진입이 가능할 때까지 Loop를 돌면서 재시도하는 방식으로 구현된 락을 가리킵니다.
운영체제의 스케쥴링 지원을 받지 않기 때문에 context switch는 발생하지 않습니다.
하지만 다른 쓰레드에게 cpu를 양보하지 않기 때문에 cpu 효율은 떨어뜨릴 수 있습니다.
뮤텍스(Mutex)
자원에 대한 접근을 동기화하기 위해 사용되는 기술입니다.
Lock을 걸은 쓰레드만 임계 영역을 나갈 때 Lock을 해제할 수 있습니다.
wait와 signal이라는 연산을 사용합니다.
스핀 락과 다르게 진입이 가능할 때까지 재시도하지 않고 sleep 상태로 들어간 상태에서 wakeup 되면 다시 권한 획득을 시도하는 방법을 사용합니다.
세마포어(Semaphore)
음이 아닌 정수 값을 가지고 쓰레드 간에 공유되는 변수를 사용합니다.
이 공유된 변수는 사용할 수 있는 자원의 개수를 의미하기도 합니다.
세마포어가 0보다 클 때마다 프로세스는 세마포어를 감소시키고 임계 구역에 들어갈 수 있도록 합니다.
세마포어가 0에 도달하면 다른 프로세스가 리소스를 해제하고 signal() 함수 호출로 세마포어를 증가시킬 때까지 프로세스는 차단됩니다.
뮤텍스와 비슷하게 wait와 signal이라는 연산을 사용하지만 뮤텍스와의 차이점으로는 Lock을 걸지 않은 쓰레드도 Lock을 해제할 수 있습니다.
교착상태(Dead Lock)란?
둘 이상의 프로세스들이 자원을 점유한 상태에서 서로 다른 프로세스가 점유하고 자원을 요구하며 무한정 기다리는 현상을 말합니다.

https://wlswoo.tistory.com/59 교착상태가 발생하기 위한 필요충분조건
아래의 네 가지 조건이 모두 충족되어야 교착상태가 발생할 수 있으며 이는 프로세스뿐만 아니라 쓰레드에서도 발생할 수 있습니다.
1. 상호 배제
한 번에 한 개의 프로세스만이 공유 자원을 사용할 수 있어야 합니다.
2. 점유와 대기
최소한 하나의 자원을 점유하고 있으며 다른 프로세스가 점유하고 있는 자원을 추가로 점유하기 위해 대기하는 프로세스가 있어야 합니다.
3. 비선점
다른 프로세스가 점유한 자원은 사용이 끝날 때까지 강제로 빼앗을 수 없어야 합니다.
4. 환형 대기
자원을 점유하며 다른 프로세스가 점유하고 있는 자원을 사용하기 위해 대기하는 프로세스들이 원형으로 자신의 앞 또는 뒤에 있는 프로세스가 점유한 자원을 요청해야 합니다.
교착 상태 해결법
교착 상태 무시
교착 상태가 드물게 발생하는 시스템에서 일반적으로 사용하는 방법 ( Windows, Unix)
교착상태가 발생하지 않는다고 가정하고 무시합니다.
사용자가 프로세스를 죽이거나 시스템을 재부팅하는 방법으로 해결합니다.
교착 상태 탐지 및 복구
교착 상태가 자주 발생하는 시스템에서 일반적으로 사용하는 방법
예방과 회피보다 일반적으로 탐지 및 복구를 사용하는 이유?
- 교착 상태는 필요악
- 교착 상태의 필요조건 중 하나를 거부하고 예방한다면 자원을 효율적으로 사용할 수 없습니다.
- 매번 교착상태를 회피하기 위해 드는 비용보다 차라리 교착상태가 발생하였을 때 탐지 및 복구하는 비용이 더 저렴합니다.
- 예를 들어 5권을 책을 빌려서 공부하려고 하는데 1권이라도 책이 존재하지 않는다면 공부를 시작하지 않는 비효율적인 방법이 될 것입니다.
교착 상태 탐지 법
순환 대기 존재 여부에 초점을 맞춥니다.
얼마나 자주 탐지 알고리즘을 호출하는지가 중요합니다.(주기적으로, 자원 즉시 할당 여부, CPU 이용률 등을 통해 탐지 알고리즘을 호출합니다)
교착 상태 복구
순환 대기가 깨질 때까지 프로세스를 종료시킴
순환 대기에 포함된 프로세스의 제어권을 뺏고 롤백
어떤 프로세스를 희생양으로 삼을 것인가?
시스템마다 다른 기준으로 우선순위에 따라지정합니다.
MySQL의 경우에는 트랜잭션 타임아웃 시 교착 상태든 아니든 가장 작은 트랜잭션을 롤백합니다.
교착 상태 회피
교착 상태를 인정하고 피해 가자
대표적으로 은행원 알고리즘(아래에서 자세히 설명)
교착 상태 예방
1. 상호 배제 부정
한 번에 여러 개의 프로세스가 공유 자원을 사용하도록 합니다.
2. 점유 및 대기 부정
프로세스가 실행되기 전 필요한 모든 자원을 할당하여 프로세스 대기를 없애거나 자원이 점유되지 않은 상태에서만 자원을 요구합니다.
3. 비선점 부정
자원을 점유하고 있는 프로세스가 다른 자원들을 요구할 때 점유하고 있는 자원을 반납하고 요구한 자원을 사용하기 위해 기다립니다.
4. 환형 대기 부정
고유번호를 할당하고 번호 순서대로 자원을 요구하도록 합니다.
은행원 알고리즘
은행에서 모든 고객이 만족할 수 있는 알고리즘에서 착안된 알고리즘으로 안전상태일 때 프로세스에 자원을 할당해주고 불안전 상태일 경우 안전상태가 될 때까지 거부합니다.
다익스트라 알고리즘을 개발한 분이 개발한 알고리즘이라고 합니다.
안전 상태란?
시스템이 교착상태를 일으키지 않으며 각 프로세스가 요구한 최대 요구량만큼 필요한 자원을 할당해 줄 수 있는 상태
불안전 상태란?
교착상태의 발생 조건이 갖추어졌을 때를 불안전 상태라고 하며 불안전 상태일 경우 무조건 교착상태가 발생하진 않습니다.
어떻게 상태를 판단할까요?
현재 자원이 12개 있고 프로세스 3개가 다음표와 같이 동작한다고 가정하겠습니다.

https://yoongrammer.tistory.com/67 Max needs : 프로세스에서 필요한 최대 자원의 수
Current allocation : 현재 프로세스에 할당된 자원의 수
Addtional need : 프로세스에서 추가로 필요한 자원의 수
Availiable resource : 이용 가능한 자원의 수
현재 Avaialbie Resource 개수는 12(현재 자원) - 5(P1 사용량)- 2(P2 사용량) - 2(P3 사용량) = 3입니다.
safe Sequnce( P2 -> P1 -> P3)로 자원을 할당과 해제가 이루어지는 부분이 있기 때문에 safe state입니다.
1. P2에 2개의 자원을 할당합니다. 3 -> 1
2. P2에서 자원을 사용하고 해제합니다. 1 -> 5
3. P1에 5개의 자원을 할당합니다. 5 -> 0
4. P1은 자원을 사용하고 해제합니다. 0 -> 10
5. P3에 7개의 자원을 할당합니다. 10 -> 3
6. P3는 자원을 사용하고 해제합니다. 3 -> 12
동일한 상황에서 다음표가 주어지면 어떻게 될까요?

현재 Avaialbie Resource 개수는 12(현재 자원) - 5(P1 사용량)- 2(P2 사용량) - 3(P3 사용량) = 2입니다.
위 상황에서는 safe sequence가 존재하지 않아 safe state는 아닙니다.
1. P2에서 2개의 자원을 할당합니다. 2 -> 0
2. P2에서 자원을 사용하고 해제합니다. 0 -> 4
3. P1 / P3는 5개와 6개의 자원이 필요하지만 4개밖에 없습니다.
즉 모두 자원을 사용할 수 없기 때문에 safe sequence가 존재하지 않고 safe state 하지 않습니다.
출처
자바의 정석 3rd Edition( 남궁 성 지음)
https://zion830.tistory.com/57(Java Concurrent 패키지)
https://enumclass.tistory.com/169(Java의 동기화 및 Locking 기법)
http://tutorials.jenkov.com/java-concurrency/volatile.html(Java Volatile Keyword)
https://yoongrammer.tistory.com/63(스핀락, 뮤텍스, 세마포어)
https://wlswoo.tistory.com/59(교착상태 DeadLock)
https://jhnyang.tistory.com/102(은행원 알고리즘이란)
https://yoongrammer.tistory.com/67(교착 상태 해결 방법)
https://www.youtube.com/watch?v=FXzBRD3CPlQ(10분 테코톡 : 둔덩의 교착상태)
'Java > 자바를 더 깊게' 카테고리의 다른 글
자바 Inner static class 로딩 시점 (0) 2022.04.10 StringBuilder의 초기화 방법 (0) 2022.03.12 [Java] Java Collection Framework의 모든것을 알아보자 (0) 2022.02.22 [Java] JVM이란? JVM(Java Virtual Machine)의 모든것을 알아보자 (2) 2022.02.17 [Java] String이 불변 객체인 이유는? (0) 2022.02.15
