-
JVM 밑바닥까지 파헤치기 - 프런트엔드 컴파일과 최적화Java 2024. 12. 22. 14:24
개요
스터디를 진행하면서 JVM 밑바닥까지 파헤치기 책의 10장 프런트엔드 컴파일과 최적화 발표를 맡게 되었고 이에 대한 내용을 정리해보고자 합니다.
프런트엔드 컴파일이란?
.java 파일을 .class 파일로 변환하는 과정을 프런트엔드 컴파일이라고 합니다.
자바 소스 코드 → 바이트코드로 변환하는 과정입니다.
반대로 백엔드 컴파일의 경우 바이트코드를 기계어로 변환하는 과정을 뜻합니다.
JIT 컴파일러가 런타임에 최적화를 수행하기도 하며, AOT 컴파일러가 특정 하드웨어용 네이티브 바이너리 코드로 곧바로 컴파일하기도 합니다.
최적화(optimization)는 무엇을 의미할까?
먼저 최적화의 사전적 의미를 찾아보면 아래와 같습니다.
1. 한정된 자원과 상황 속에서 최대한의 성능을 발휘할 수 있도록 끌어올리는 행위, 다시 말해 효율을 높이는 행위.
2. 보통은 저 '성능'이 속도만을 의미하는 경우가 많지만 문맥에 따라 비용, 재료, 힘, 업무 생산성 등을 뜻하기도 한다.
하지만 프런트엔드 컴파일 단계에서 코드 실행 효율 측면의 최적화는 거의 수행하지 않으며 성능 최적화는 백엔드 컴파일러에게 위임합니다.
거의 수행하지 않는다고 한 이유는 아래에서 설명할 상수 접기, 조건부 컴파일, String + 연산자 최적화 등을 수행하기 때문입니다.
그렇다면 프런트엔드 컴파일 최적화란?
위 2가지 개념을 조합해 보면 프런트엔드 컴파일 최적화는 아래와 같이 이야기할 수 있습니다.
프런트엔드 컴파일 최적화란 최적화의 범위를 개발 단계까지 포함시켜 코드를 작성하는 개발자의 업무 생산성을 높입니다.
프런트엔드 컴파일러는 제네릭, 오토박싱, 오토언박싱, 개선된 for 문 등의 편의 문법을 해석해 줍니다.
이외에 try-with-resources, 람다 표현식, switch 표현식, record 들도 편의 문법에 속합니다.
즉, 내부적으로 바이트코드로 컴파일해 주어 개발자가 작성하는 코드를 단순화하는 역할을 수행합니다.
javac 컴파일러 소스코드 분석
또한 프런트엔드 컴파일러는 javac 컴파일러라고도 부릅니다.
앞으로는 프런트엔드 컴파일러를 javac 컴파일러라고 계속 부르겠습니다.
핫스팟 가상 머신의 경우 c++/ c 로 구현되어 있지만 javac 컴파일러는 순수하게 자바로 구현되어 있습니다.
따라서 원한다면 자바 개발자는 컴파일 과정을 이해하기 위해 소스코드를 보며 디버깅해 볼 수 있습니다.
javac 컴파일러 명세
자바 가상 머신 명세의 3장 Compling for the Java Virtual Machine을 살펴보면 자바 코드를 어떤 바이트 코드로 변환해야 하는지에 대한 예만 나와 있습니다.
javac를 바이트 코드로 컴파일하는 방법이 느슨하기 때문에 높은 자유도를 가질 수 있습니다.
이로 인해 컴파일 과정이 특정 JDK 또는 컴파일러의 구현에 따라 달라질 수 있으며 극단적으로는 javac로는 컴파일할 수 있지만 ECJ( Eclipse Compiler for Java) 로는 컴파일할 수 없는 코드가 생길 수 있습니다.
javac의 컴파일러의 컴파일 단계
실제 JavaComplier 클래스가 아래 역할을 수행하게 됩니다.
0단계 - 플러그인 애너테이션 처리기들 초기화
1단계 - 어휘 및 구문 분석, 심벌 테이블 채우기
2단계 - 플러그인 애너테이션 처리기들로 애너테이션 처리
3단계 - 문법의 정적 정보 확인, 동적 실행 과정 확인, 편의 문법 제거, 바이트 코드 생성
각 단계들을 자세하게 알아보겠습니다.
어휘 및 구문 분석
어휘 분석은 소스 코드를 토큰 집합으로 변환하는 일을 수행합니다.
int a= b + 2 의 경우 (int, a, =, b, +, 2) 토큰 집합으로 총 6개의 토큰으로 변하게 됩니다.
int는 키워드 이므로 더 작은 토큰으로 쪼개지지 않습니다.
구문 분석은 토큰의 집합을 추상 구문 트리로 구성하는 과정입니다.
이 단계에서 언어의 spec으로 정해진 문법 구조가 아니라면 컴파일 에러가 발생하게 됩니다.

https://en.wikipedia.org/wiki/Compiler 심벌 테이블 채우기
심벌(Symbol)은 프로그래밍 언어나 컴파일러에서 변수, 함수, 클래스, 상수 등 이름이 붙은 식별자를 지칭하는 용어입니다.
쉽게 말해, 프로그램 소스 코드에서 사용자가 정의한 이름들이 바로 심벌입니다.
val age = 25 fun calculate(): Int { return age * 2 }위 코드에서 심벌은 다음과 같습니다:
- 변수 심벌: age
- 함수 심벌: calculate
심벌 테이블은 심벌 주소와 심벌 정보의 집합으로 구성된 데이터 구조로 해시 테이블을 떠올리면 됩니다.
이 정보는 컴파일 과정 곳곳에서 활용됩니다. (의미 분석, 목적 코드의 생성 단계 주소 할당)
애너테이션 처리
JDK 5부터 애너테이션이 지원되기 시작했고, JDK6부터 플러그인 할 수 있는 애너테이션 처리 API 표준이 도입되었습니다. (JSR 269)
Java를 개발할 때 주로 사용했던 Lombok을 떠올리면 좋습니다.
컴파일 타임에 미리 처리될 수 있기 때문에 프런트엔드 컴파일러의 동작에 영향을 주며 추상 구문 트리의 임의 요소를 읽고 수정하고 추가할 수 있습니다.
만약 플러그인 애너테이션 처리기가 구문 트리를 수정하게 되면 구문 분석 및 심벌 테이블 채우기 단계로 돌아가며 이 단계를 구문 트리가 수정되지 않을 때까지 반복합니다.
기존에는 수동으로 코딩할 수밖에 없었던 작업을 이 처리기를 통해 getter/setter 생성, null 확인, equals(), hashcode 생성 등으로 개발자의 수고를 덜어줍니다.
플러그인 애너테이션 처리기는 잠시 뒤 실습으로 만들어보겠습니다.
의미 분석과 바이트코드 생성
앞서 설명했던 추상 구문 트리는 코드를 구조화해 주지만 의미 체계가 논리적인지는 검사하지 못합니다.
타입 검사, 제어 흐름 검사, 데이터 흐름 검사 작업을 수행하여 IDE 환경에서 코드에 빨간 밑줄로 오류를 표시하게 됩니다.
이 과정에서 상수 접기와 같은 몇 안 되는 최적화도 수행합니다.
상수 접기는 int a = 1+ 2; 로 선언되어 있는 경우 int = 3 으로 선언한 것과 동일하게 최적화합니다.
final 한정자에 대한 이야기도 나오는데 final을 붙인 코드와 붙이지 않은 코드는 바이트코드에 아무런 차이가 없습니다.
변수의 불변성은 오직 javac 컴파일러에 의해서만 보장됩니다.
편의 문법 제거(desugar)도 이 과정에서 수행됩니다.
편의 문법은 개발자가 언어를 쉽게 다룰 수 있도록 편의성을 위해 제공되는 문법입니다.
컴파일 과정 중 편의 문법이 제거되고 원래의 기본 구문 구조로 변경합니다.
편의 문법의 예시로는 제네릭, 오토박싱, 오토언박싱, 개선된 for 문, try-with-resources, 람다 표현식, switch 표현식, record 들이 존재합니다.
마지막 단계로는 구문 트리, 심벌 테이블 정보를 기반으로 바이트코드가 생성됩니다.
이 과정에서 소량의 코드가 추가되거나 변경될 수 있습니다.
예를 들어 사용자가 생성자를 제공하지 않으면 컴파일러는 심벌 테이블 채우기 단계에서 기본 생성자를 추가합니다.
인스턴스 생성자 <init>() 클래스 생성자 <cinit>() 등이 구문 트리에 추가됩니다.
이외에도 + 연산자를 사용한 문자열 합치기를 StirngBuffer나 StringBuilder의 append 코드로 대체하여 최적화를 수행하기도 합니다.
편의 문법 제네릭의 역사
2004년에 JDK 5와 C# 2.0이 발표되었고 우연히 모두 제네릭이 추가되었습니다.
하지만 제네릭을 구현하는 방식은 매우 다른 길을 택하게 되었습니다.
이 때문에 수많은 분석과 논쟁이 이루어졌고 결론은 "자바의 제네릭은 C#의 제네릭보다 사용하기 어렵다"라고 합니다.
하지만 자바의 제네릭 메커니즘과 역사를 알게 되면 설계자의 수준이 C# 보다 못해서는 아님을 이해할 수 있으며 이는 당시에 선택한 최선의 절충안입니다.
자바에서 구현한 제네렉을 타입 소거 제네릭이라고 하며 C#에서 구현한 제네릭을 구체화된 제네릭이라고 합니다.
자바는 컴파일 과정에서는 타입정보가 사라지지만 C#은 구체적인 정보가 남아있습니다.
자바에서 제네릭을 활용하면 컴파일타임에만 존재하고 타입 정보가 바이트코드에서는 사라집니다.
즉, 자바에서는 ArrayList<Integer> 와 ArrayList<String> 의 타입이 런타임에서는 동일합니다.
아래 소스코드는 타입소거로 인해 런타임에 동일함을 명확하게 보여줍니다.
val slist = ArrayList<String>() val ilist = ArrayList<Integers>() println(slist.javaClass) // 출력: class java.util.ArrayList println(ilist.javaClass) // 출력: class java.util.ArrayList아래 소스코드는 C# 대비 자바의 코드 작성 불편함과 성능하락을 보여주는 예제입니다.

Cannot check for instance of erased type: E 런타임에서는 E 타입 정보가 소거되므로 인스턴스 여부를 판단할 수 없게 되고 컴파일에러가 발생하게 됩니다.
자바에서는 박싱, 언방식이 이루어져야 하며 이를 막기 위해서는 IntFloatHashMap 등을 직접 구현해야 하는데 이렇게 되면 제네릭의 존재 가치가 떨어지게 됩니다.
다만 호환 범위 측면에서는 변환과정을 javac 컴파일러가 온전하게 담당하므로 바이트코드나 자바 가상 머신은 변경하지 않아도 됩니다.
덕분에 제네릭을 사용하지 않는 라이브러리도 JDK 5 이상에서 곧바로 실행될 수 있습니다. (하위호환성)
제네릭이라는 아이디어는 1996년부터 도입하려는 시도가 있었고 제네릭, 고차 함수, 패턴 매칭을 추가하여 스칼라의 전신인 Fizza라는 언어를 탄생시켰습니다.
처음부터 타입 소거 제네릭은 목표가 아니었고 C#과 가까운 제네릭이었지만 자바 언어 명세에 약속된 spec인 바이너리 하위 호환성을 지키기 위해 타입 소거 제네릭을 선택하게 됩니다.
제네릭이 없던 시대의 아래의 자바 소스코드도 문제없이 컴파일되어야 합니다.

IDE가 수많은 경고를 제시합니다 이 상황에서 선택지는 2가지입니다.
1. 제네릭이 필요한 타입(컨테이너 타입)중 일부는 그대로 두고 제네릭 버전을 따로 추가한다.
2. 제네릭이 필요한 모든 기존 타입을 제네릭 버전으로 변경한다.
C#은 첫 번째 방법을 택하여 기존의 System.Collections와 System.Collections.Specialized를 유지한 채 System.Collections.Generic 에 새로운 컨테이너들을 추가하였습니다.
그러면 Java는 왜 이런 선택을 하지 않았을까요?
하지만 C# 은 두 살배기 신생 기술이었지만 Java는 10년이 된 언어이므로 레거시 코드에 비교할 수 없는 간극이 있었습니다.
그리고 과거에 이미 첫 번째 기술적 선택을 한 사례가 이미 존재했습니다.
Vector 대신 ArrayList, Hashtable 대신 HashMap으로 두 벌의 컨테이너 코드가 공존하고 있었으며 제네릭까지 추가된다면 Vector<T>, ArrayList<T> 등의 4벌의 컨테이너 API 가 제공되게 됩니다.
하지만 두 번째 방법을 채택했다고 해서 타입 소거 형태로 구현해야 한다는 뜻은 아닙니다.
시간이 충분했다면 더 나은 방식으로 구현할 수 있었으며 이때의 기술부채를 갚기 위해 발할라 프로젝트가 진행 중입니다.
발할라 프로젝트는 Java 플랫폼에서 성능과 메모리 효율성을 개선하기 위해 진행 중인 대규모 혁신 프로젝트입니다.
타입 소거의 구현방식과 단점
ArrayList<Integer> ilist = new ArrayList<Integer>(); ArrayList list; list = ilist; // 제네릭 타입의 인스턴스 할당 허용안전한 형변환을 위해 ArrayList<T> 인 ArrayList<Interger> 는 ArrayList의 하위타입이 되어야 합니다.
책에서는 공통 상위타입인 ArrayList를 원시타입이라고 부릅니다.
(여기서 말하는 원시타입은 primitive type 이 아닌 raw type 인 것 같습니다.)
그러면 JVM은 원시타입을 어떻게 구현할까요?
1. JVM이 런타임에 자동 생성하는 방식
2. 컴파일타임에 제네릭 타입을 원시 타입으로 변환하며 필요한 형 변환 코드를 적절히 추가하여 추가/수정될 때 확인하는 방식
실제 아래 제네릭 코드를 컴파일하고 바이트코드로 디컴파일하면 어떻게 될까요?
ArrayList<String> list = new ArrayList<>(); list.add("Hello"); String str = list.get(0);마치 제네릭을 사용하지 않은 코드처럼 변환하게 됩니다.
ArrayList list = new ArrayList(); // 제네릭 타입 정보 제거 list.add("Hello"); String str = (String) list.get(0); // 형 변환 코드 추가단점 1 - 제네릭이 기본 타입 데이터를 지원하는 방법
자바는 int, long, Object 사이의 직접적인 형 변환을 지원해주지 않아서 ArrayList<Integer> 과 ArrayList<Long>과 같은 래퍼 클래스 버전을 활용하여 박싱/언박싱을 수행합니다.
이로 인해 제네릭의 속도를 떨어뜨리는 주된 원인이 되었습니다.
단점2 - 우아하지 않은 코드 (장황한 코드)
inline fun <reified T> createList(size: Int, defaultValue: T): List<T> { return MutableList(size) { defaultValue } } // 타입 정보를 전달해야 하는 경우 fun <T> createArray(type: Class<T>, size: Int): Array<T?> { return java.lang.reflect.Array.newInstance(type, size) as Array<T?> } fun main() { // 런타임에 타입 정보를 전달해야 하는 경우 val intArray = createArray(Int::class.java, 5) intArray[0] = 1 // 값 추가 println(intArray.joinToString()) // 출력: 1, null, null, null, null // 타입 정보를 런타임에 전달하지 않아도 되는 경우 (reified 사용) val stringList = createList(5, "Hello") println(stringList) // 출력: [Hello, Hello, Hello, Hello, Hello] }자바 가상 머신이 실제 타입을 알 수 없기 때문에 원소타입에 대한 정보를 매개 변수로 전달해주어야 합니다.
다만 kotlin의 경우 reified 키워드를 통하여 제네릭 타입 정보를 런타임까지 유지할 수 있습니다.
단점3 - 객체지향적으로 모호한 코드
fun method(list: List<String>) { println("List of Strings: $list") } fun method(list: List<Int>) { // 컴파일 에러 발생 println("List of Integers: $list") } fun main() { method(listOf("Hello", "World")) method(listOf(1, 2, 3)) // 두 번째 method 호출은 컴파일 에러 발생 }제네릭의 타입 소거로 인해 두 메서드의 시그니처를 동일하게 만들어 오버로딩이 불가능해집니다.
제네릭의 등장으로 구문 분석과 리플랙션 등 다양한 시나리오 메서드 호출 구현에 영향을 주게 되었습니다.
제네릭 클래스 타입에서 입력 매개 변수를 얻는 방법과 같은 새로운 요구사항을 충족시키기 위해 자바 가상 머신 명세로 약간 수정되었습니다.
Signature와 LocalVariableTypeTable과 같은 새로운 속성이 도입되었습니다.
Signature는 메서드의 시그니처를 바이트코드 수준으로 저장합니다.
즉, Signature를 사용하면 런타임에서도 제네릭 타입을 인식할 수 있도록 지원합니다.
이로 인해 JDK 5 이상에서의 모든 가상 머신은 Signature 매개 변수를 올바르게 인식해야 한다고 규정되었습니다.
편의 문법의 오 사용 사례 - 오토방식, 언박싱
오토방식 언박싱은 편의 문법 중 하나의 예제이며 제네릭은 raw type으로 변환되며 Integer.valueOf()와 Integer.intValue() 메서드에 의해 래퍼 타입과 primitive type으로 변환됩니다.
void test(){ Integer a = 1; Integer b = 2; Integer c = 3; Integer d = 3; Integer e = 321; Integer f = 321; Long g = 3L; System.out.println(c == d); // 3 == 3 -> true System.out.println(e == f); // 321 == 321 -> false System.out.println(c == (a + b)); // 3 == 2 + 1 -> true System.out.println(c.equals(a + b)); // 3 == 2 + 1 -> true System.out.println(g == (a + b)); // 3L == 1 + 2 -> false System.out.println(g.equals(a + b)); // 3L == 1 + 2 -> false }가장 중요한 것은 이 모든 과정을 이해하고 있더라도 실무에서 오토박싱/언박싱을 이런 형태로 사용하는 건 피해야 합니다.
첫 번째의 경우 c와 d의 경우 Integer 객체로, 값이 동일 (3)입니다.
Java에서는 Integer 객체가 값이 -128에서 127 사이일 경우 캐싱되어 같은 객체를 참조합니다.
반면 두 번째의 321의 경우에는 캐싱되지 않아 두 객체가 다른 메모리 주소를 가리킵니다.
세 번째의 경우 a + b 가 int로 계산된 후 자동박싱이 발생하여 Integer 3 객체로 변환되어 캐싱에 의해 동일하게 true가 반환됩니다.
다섯 번째의 경우 g는 Long 타입입니다. a + b 는 int로 계산 후 Integer로 변환되므로 false로 됩니다.
조건부 컴파일
if(true) , if(false) 와 같이 조건문에 상수를 넣는 경우 디컴파일시 실행될 수 없는 영역을 제거하거나 도달할 수 없는 경우 컴파일러가 오류를 내기도 합니다.
실전 - 플러그인 애터네이션 처리기 제작
@ShouldInterface 어노테이션을 붙이면 interface 형태를 강제하는 기능을 가진 플러그인 애너테이션 처리기를 제작해 보겠습니다. (우리가 흔히 아는 플러그인 애너테이션 처리기는 Lombok)
첫 번째로 @ShouldInterface 어노테이션을 annotation-holder 모듈에 정의합니다.

두 번째로 annotation-processor-maker 모듈에 AbstractProcessor()를 구현합니다.
이 모듈은 @ShouldInterface을 활용하기 위해 annotation-holder 모듈을 활용합니다.
@AutoService(Processor::class) class ShouldInterfaceProcessor : AbstractProcessor() { override fun getSupportedAnnotationTypes(): Set<String> { return mutableSetOf(ShouldInterface::class.java.name) } override fun getSupportedSourceVersion(): SourceVersion { return SourceVersion.latestSupported() } override fun process(annotations: Set<TypeElement?>?, roundEnv: RoundEnvironment): Boolean { //ShouldInterface 이라는 애노테이션을 가지고있는 엘리먼츠를 가지고 온다. val elements: Set<Element> = roundEnv.getElementsAnnotatedWith(ShouldInterface::class.java) for (element in elements) { val elementName: Name = element.getSimpleName() if (element.getKind() !== ElementKind.INTERFACE) { // 엘리먼츠가 인터페이스가 아닐 경우 에러 출력 processingEnv.messager.printMessage( Diagnostic.Kind.ERROR, "ShouldInterface annotation can not be used on $elementName" ) } else { processingEnv.messager.printMessage(Diagnostic.Kind.NOTE, "ShouldInterface annotation Processing $elementName") } } return true } }AbstractProcessor는 추상클래스로 javax.annotation.processing 패키지에 속합니다.
이 클래스는 하나의 process 추상 메서드만 구현하면 되며 첫 번째 매개변수인 annotations 으로부터 처리할 애너테이션 집합을 얻고, 두 번째 매개 변수인 roundEnv를 통해 추상 구문 트리 노드에 접근할 수 있습니다.
위 코드를 살펴보면 ShouldInterface 인 어노테이션의 Element를 가져온 후 ElementKind가 INTERFACE인 경우 컴파일 에러를 출력하도록 합니다.
JDK 17 기준으로 ElementKind는 21가지이며 필드, 메서드, 클래스 등이 존재합니다.
만약 @AutoService 라이브러리를 활용하지 않는다면 resources/META-INF/services 경로에javax.annotation.processing.Processor 파일을 만들고 어노테이션 프로세서의 패키지 경로를 적어주어야 합니다. (@AutoService가 위의 기능을 수행해 주어 편리함을 제공합니다.)
세 번째로 front-compiler-annotation-plugin 모듈을 구성하고 @ShouldInterface 어노테이션에 class를 활용하여 컴파일을 돌리면 아래 사진처럼 실패하는 모습을 볼 수 있습니다.
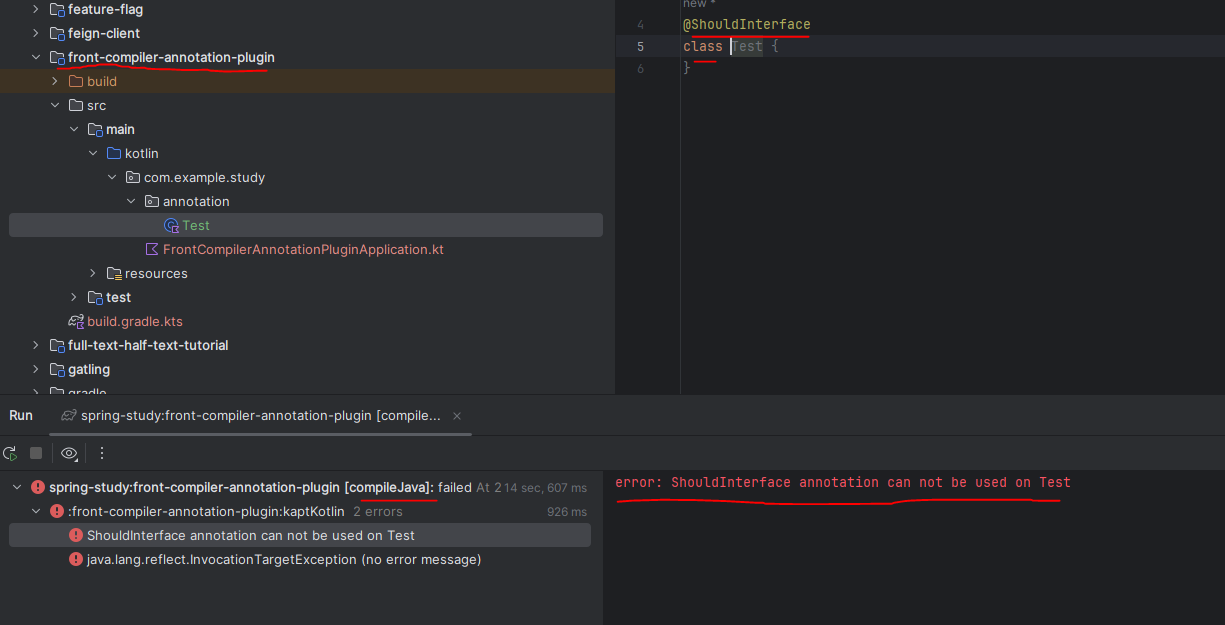
printMessage로 정의한 error가 사용자에게 노출되며 만약 class를 interface로 변경하면 컴파일에 통과됩니다.
주의할 점으로는 java에서는 모듈을 불러올 때 annotationProcessor를 활용해야 하고 kotlin에서는 kapt를 활용해야 합니다.
dependencies { implementation(project(":annotation-holder")) kapt (project(":annotation-processor-maker")) }kapt(Kotlin Annotation Processing Tool)는 Kotlin 코드를 중간 단계에서 Java로 변환하여 Java 어노테이션 프로세서가 이를 처리할 수 있도록 돕습니다.
마무리
Kafka Consumer에서 enum type을 사용하지 못하도록 하기 위해 ArchUnitTest로 해소했던 케이스가 존재하는데 프런트엔드 컴파일러를 활용해서 컴파일이 되지 않도록 해소해 볼 수도 있을 것 같습니다.
해당 챕터를 공부하며 기존의 lombok 등이 어떻게 동작하는지 잘 이해하게 되었고 queryDSL 등을 활용할 때 kapt에서 이슈가 생기면 파악하는데 더 도움이 될 것 같습니다.
또한 kotlin이 java의 단점을 보완하기 위해 꽤 많은 것들을 제공해 줌을 알게 되었습니다.
참고자료
서적 - JVM 밑바닥까지 파헤치기
https://docs.oracle.com/javase/specs/jvms/se7/html/jvms-3.html
https://eottabom.github.io/post/lombok-process/
'Java' 카테고리의 다른 글
BigDecimal이란? (0) 2024.01.10 구독의 보너스 날짜 계산하기 (0) 2023.09.19 Throwable 클래스란? (0) 2023.06.16 Instant vs LocalDateTime (0) 2023.05.27 [Java] 날짜,시간과 관련된 LocalDateTime의 역사 (0) 2022.08.27