-
spin lock 대신 Thread Waiting을 활용하면 성능이 얼마나 개선될까?성능테스트 2024. 11. 23. 09:38반응형
개요
spin lock 방식에서 cpu의 리소스가 얼마나 점유될지 궁금하여 성능 테스트하면서 글을 작성했습니다.
만약 spin lock 방식 대신 Thread Sleep 방식을 적용하면 cpu의 성능이 얼마나 개선될 수 있을까요?
Thread Sleep 방식을 알아보기 전에 임계영역을 점유하는 방법인 metux에 대해 알아보겠습니다.
mutex란?

Mutex는 특정 구현보다는 이론적인 용어로써 임계 영역에 여러 스레드가 경합하는 것을 방지합니다.
Thread A는 임계 영역에 들어가기 전 lock을 점유합니다.
이후 Thread B가 Thread A가 접근한다면 임계 영역에 진입하지 못하고 기다려야 합니다.
이후 Thread A가 unlock을 수행하면 Thread B가 접근할 수 있습니다.
일상생활적으로 접근해보면 여러 구성원(스레드)이 참가한 회의에서 발언권(임계영역)을 갖기 위해 공(Mudex)을 가진 사람만 발언하는 것을 떠올려볼 수 있습니다.
Mutex를 실제로 구현하는 방법으로 synchronized, ReentrantLock, Semaphore, Monitor 등을 활용해 볼 수 있습니다.
처음에 개념적으로 조금 헷갈렸는데 결국 mutex는 spin lock 혹은 Thread Sleep 방식과는 관계없습니다.
Spin Lock 방식
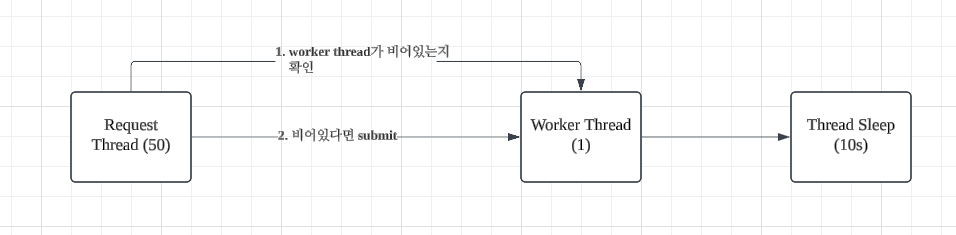
50개의 Request Thread가 Worker Thread 라는 임계영역으로 들어가기 위해 worker thread의 activeCount가 1개 미만인지 지속적으로 spin-waiting 방식으로 체크합니다.
이후 비어있다면 submit을 통해 임계영역으로 진입시키고 다시 남은 request가 있으면 spin-waiting 합니다.
worker thread는 내부적으로 10초후에 작업을 완료한다고 가정하였습니다.
성능 테스트시 cpu는 11 % 점유하게 됩니다.
아래는 샘플코드입니다.
@RestController class TestController { val requestThread : ThreadPoolExecutor = Executors.newFixedThreadPool(REQUEST_HOLD_THREAD_COUNT) as ThreadPoolExecutor val threadPool: ThreadPoolExecutor = Executors.newFixedThreadPool(THREAD_COUNT) as ThreadPoolExecutor val worker = Worker() @PostMapping("/spin-lock-test") fun runSpinLock(){ repeat(50){ requestThread.submit { println("current Active requestThread = ${requestThread.activeCount}") while(true){ if(threadPool.activeCount < THREAD_COUNT){ threadPool.submit { worker.doSomething() } break } } } } } companion object{ const val THREAD_COUNT = 1 const val REQUEST_HOLD_THREAD_COUNT = 50 } } class Worker { fun doSomething() { sleep(1000 * 10) println("job is finish") } }cpu를 5초 주기로 수집하여 로깅해 주는 방법
@Component class CpuMonitoringScheduler { private val restTemplate = RestTemplate() private val cpuUsageThreshold = 0.001 @Scheduled(fixedRate = 5000) // 5초 간격으로 cpu 지표 수집 fun monitorCpuUsage() { val url = "http://localhost:8080/actuator/metrics/process.cpu.usage" val response = restTemplate.getForObject(url, CpuUsageResponse::class.java) val cpuUsage = response?.measurements?.firstOrNull()?.value ?: 0.0 // 0.001 보다 낮으면 0%로 보여줍니다. val displayCpuUsage = if (cpuUsage < cpuUsageThreshold) { 0.0 } else { cpuUsage } // CPU Usage를 %로 출력 logger.info("CPU Usage: ${"%.2f".format(displayCpuUsage * 100)}%") } } data class CpuUsageResponse( val name: String, val measurements: List<Measurement> ) data class Measurement( val statistic: String, val value: Double )Thread Sleep을 추가해보자
현재 작업은 특성상 10초를 기다려야 하는데 반복문으로 지속적으로 체크하는 게 비효율적으로 느껴질 수 있습니다.
spin waiting 하는 방식에서 1000ms의 주기를 추가하면 cpu 사용량 효율성은 어떻게 개선될까요?
cpu의 사용량이 0.001% 이하로 보입니다.
1000ms가 아닌 100ms, 10ms로 세팅해도 cpu를 계속 일하게 하지 않고 sleep만 잠깐 추가해도 극단적으로 효율이 개선됩니다.
하지만 특정 기간을 기다리게 하는 것은 동적으로 끝나는 시간이 달라질 수 있는 환경에서는 최적의 해결책은 아닌 것 같습니다.
만약 어떤 작업이 1초, 2초 ~ 9초, 10초 등으로 랜덤 하게 끝나면 어떤 주기로 sleep을 주는 게 좋을까요?
LockSupport 활용하기
JDK 1.5 이상부터 제공되는 LockSupport의 park와 unpark 메서드를 활용해 볼 수 있습니다.
park 메서드는 현재 thread를 blocking 합니다.
blocking을 해제하고 싶은 스레드를 인자로 넣어 unpark 메서드를 호출해 볼 수 있습니다.
javadocs에 명시된 주의사항으로는 unpark 메서드를 호출하지 않더라도 이유 없이 blocking이 해제될 수 있으므로 항상 스레드의 blokcing이 해제되면 특정 조건을 만족했다고 로직을 작성하면 안 됩니다.
@PostMapping("/spin-lock-test") fun runSpinLock(){ repeat(50){ requestThread.submit { println("current Active requestThread = ${requestThread.activeCount}") val currentThread = Thread.currentThread() while(true){ if(threadPool.activeCount < THREAD_COUNT){ threadPool.submit { worker.doSomething() LockSupport.unpark(currentThread) } break } LockSupport.park() } } } }모든 스레드가 실행 중이라면 park() 메서드를 호출하고 로직을 모두 수행하고 나서는 현재 스레드를 인자로 넣어 unpark() 메서드를 호출하는 방식입니다.
실제 cpu 자원 소모는 0.001% 이하로 소모하여 thread.sleep() 방식과 큰 차이가 보이지 않습니다.
LockSupport와 CAS 연산
LockSupport의 javadoc은 park와 unpark 메서드를 활용할 때는 atomic 변수를 활용하여 제어하라고 하며 예시를 제공합니다.
AtomicBoolean의 compareAndSet 메서드를 활용한 예제입니다.
import java.util.Queue; import java.util.concurrent.ConcurrentLinkedQueue; import java.util.concurrent.atomic.AtomicBoolean; import java.util.concurrent.locks.LockSupport; public class FIFOMutex { private final AtomicBoolean locked = new AtomicBoolean(false); private final Queue<Thread> waiters = new ConcurrentLinkedQueue<>(); public void lock() { boolean wasInterrupted = false; // Publish current thread for unparkers waiters.add(Thread.currentThread()); // Block while not first in queue or cannot acquire lock while (waiters.peek() != Thread.currentThread() || !locked.compareAndSet(false, true)) { LockSupport.park(this); // Ignore interrupts while waiting if (Thread.interrupted()) { wasInterrupted = true; } } waiters.remove(); // Ensure correct interrupt status on return if (wasInterrupted) { Thread.currentThread().interrupt(); } } public void unlock() { locked.set(false); LockSupport.unpark(waiters.peek()); } static { // Reduce the risk of "lost unpark" due to classloading Class<?> ensureLoaded = LockSupport.class; } }compareAndSet(false, true)의 경우 변수가 false인 경우 true로 업데이트하며 true를 반환합니다.
만약 locked 변수가 true로 락을 이미 점유하고 있다면 false를 반환하는데 ! 부정문이 붙어있으므로 while 문 안으로 진입하여 park 메서드의 호출합니다.
반면 locked 변수가 false인 경우 락을 점유하고 있지 않으므로 locked를 true로 세팅하고 true를 반환하는데 ! 부정문이 붙어있어 false가 되어 park 메서드가 호출되지 않습니다.
이후 unlock을 수행할 때는 locked를 false로 세팅하고 unpark 메서드를 호출합니다.
이처럼 locked 변수에 compareAndSet(true, false)를 조건문으로 세팅한다면 락이 점유되었을 때만 park이 호출되도록 오버헤드를 줄일 수 있습니다.
Spin Lock과 Thread Waiting 트레이드 오프 고려
Spin Lock과 Thread Waiting 방법은 모두 임계영역에 안전하게 진입하기 위해 사용되는 기법입니다.Spin Lock은 Context Switching 비용이 없는 대신 임계영역에 진입하기 위해 CPU를 지속적으로 활용합니다.따라서 ms 단위의 짧은 시간 내에 임계영역 진입이 가능할 것으로 예상될 때 활용해볼 수 있습니다.반면 Thread Waiting은 Thread가 Waiting 상태로 변경되기 때문에 Context Switching 비용이 발생하므로 ms 이상 단위의 비교적 긴 시간동안 소요될 경우가 예상될 때 활용해볼 수 있습니다.성능 테스트상은 spin lock이 비효율적으로 보이지만 단편적인 상황이므로 두 가지 방법중 하나를 선택할때는 트레이드 오프를 고려하여 선택해볼 수 있습니다.참고자료
https://www.baeldung.com/cs/what-is-mutex
https://www.baeldung.com/java-mutex
https://www.baeldung.com/java-lang-thread-state-waiting-parking
'성능테스트' 카테고리의 다른 글
spin lock은 cpu에 얼마나 부하를 줄까? (3) 2024.10.07 Gatling으로 성능테스트 하기 (0) 2023.11.20 [Mac] homebrew jmeter 설치 및 테스트 (0) 2023.11.19 Tomcat Thread의 수는 얼마나 늘리는게 좋을까? (1) 2023.08.09 JVM Memory Leak 만들고 탐지, 개선하기 (2) 2023.07.14